
Liberating HTML Data Tables
It’s not uncommon to see small data sets published on the web using an HTML table element. If you have a quick click around Wikipedia, you’re likely to find a wide variety of examples. Some sites will use Javascript libraries to enhance the presentation or usability of a table, for example, by making columns sortable; but most of the time, we are faced with a flat HTML table, and the data locked in it.
In this section, we look at some quick tricks for liberating data from HTML tables on public webpages and turning them into something more useful.
Screenscraping HTML Tables Using Google Spreadsheets
The Google spreadsheet formula:
=importHTML("","table",N)
will scrape a table from an HTML web page into a Google spreadsheet. The URL of the target web page, and the target table element both need to be in double quotes. The number N identifies the N’th table in the page (counting starts at 1) as the target table for data scraping.
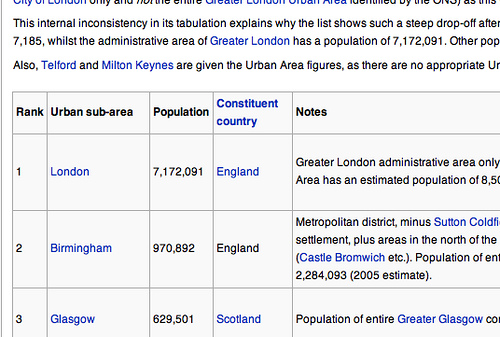
So for example, have a look at the following Wikipedia page – List of largest United Kingdom settlements by population (found using a search on Wikipedia for UK city population):
Grab the URL, fire up a new Google spreadsheet, and start to enter the formula =importHTML into one of the cells:
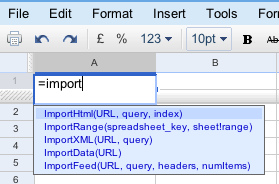
Autocompletion works a treat, so finish off the expression and add in the URL and table number:
excel
=importHTML("http://en.wikipedia.org/wiki/List_of_largest_United_Kingdom_settlements_by_population","table",2)
The table numbers are not always obvious - start with 1 and increment the table number until you get the correct one.

As if by magic, a data table appears in the spreadsheet, pulled in directly from the Wikipedia page:
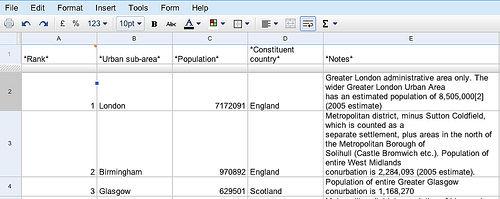
If the data in the HTML table is updated, the data in the spreadsheet will also be updated when you refresh or call the spreadsheet page.
- Improve this page Edit on Github Help and instructions
-
Donate
If you have found this useful and would like to support our work please consider making a small donation.