
Diffing and patching tabular data
A few years ago at the Eastern Conference for Workplace Democracy in New Hampshire, a bunch of friends chatting on a grassy knoll realized they were all working on overlapping directories of their communities, and decided to pool their efforts. They tracked down some techies (I was one) and set them to work building a directory website. Someone should have warned them about techies.

Eight years later, okay there is a directory website, but the project has morphed into something a lot more ambitious:
- A full-blown co-op to deal with the cultural and legal side of data sharing. This is the Data Commons Co-op.
- A growing toolbox to deal with the technological side of data sharing, specifically how to have fun (rather than get depressed) collaborating on data projects. This is the Coopy Toolbox.
We, like others in the Open Data world, have been asking: where’s the
git(hub) for data? More fundamentally, where’s the diff and patch
programs for data? Where’s something like diff3 for doing 3-way
merges? Can we bring the whole free and open toolchain of diffing,
patching, merging, and version control to the world of data?
The toolchain is there already, for some
Fun data collaboration is possible today by inventive use of existing tools, as Rufus Pollock has noted. Here’s an example of a pull request found in the wild, made to a repository on github that tracks some bus routes in Iceland in regular CSV files:
https://github.com/gudmundur/straeto-data/pull/4
“Fixed stops on the wrong side”
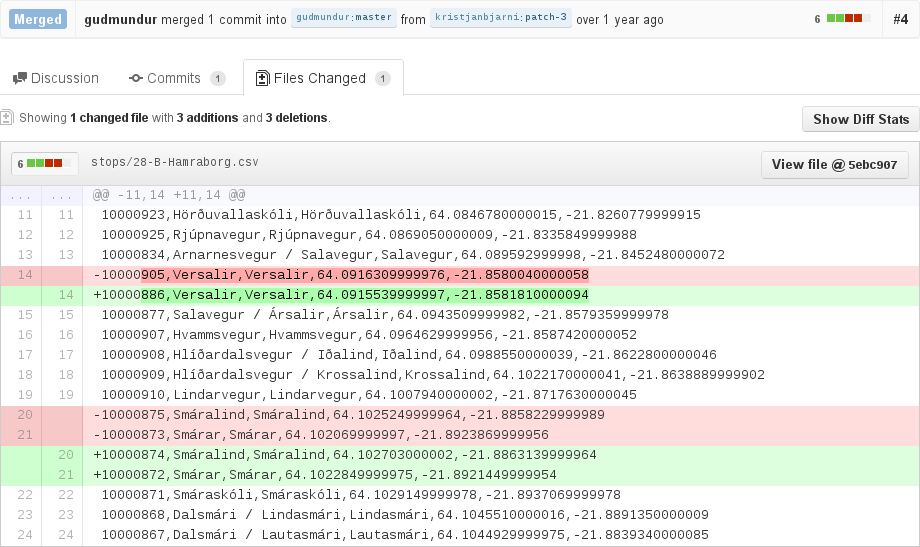
I’m a bit embarrassed to remember how excited I was to
stumble across this real live data-oriented pull request. I ran around showing people, saying
“this!” “this!” (One of those moments when
you realize: you really are a nerd). Some asked, why is this better than,
for example, a shared spreadsheet online, edited live? For the same reason that git and hg were so much more
exciting than svn and cvs. The awful artificial problem of
who to bestow write-access upon and who to keep outside the clique
just evaporates,
and the equivalent of social coding kicks in.
There are definitely some technical drawbacks to working this way today though. For example: what happens when things go wrong? A poor merge or a merge conflict in a text file still results in a text file, which a user can edit as usual to fix up. Text file in, text file out. But a poor merge or a conflict in a CSV file can leave you with an invalid CSV file with missing/surplus columns on some rows, or with conflict markers inserted. This bumps the user out of Gnumeric/LibreOffice/Excel/Sqlite/… or whatever they are using to edit the table, and leaves them staring at randomly garbled text. Another problem: column changes look awful in line-oriented diffs, which isn’t a deal-breaker but which is certainly a pity. We can do better.
A diff for (tabular) data
There didn’t seem to be any neutral format for comparing tables out there when I went looking. SQL could be abused to serve (DELETE clauses to express rows removed, INSERTs rows added, UPDATEs for modified cells, etc) but I couldn’t see that leading anywhere happy. My first idea was to express diffs as tables in CSV form, as a list of operations. This was ugly. Then Joe Panico of http://www.diffkit.org and I hammered out something we called TDIFF, “tabular diff format”, very much inspired by classic diffs, with added awareness of columns. This was better, but still felt a bit clunky. Finally, I settled on what now seems obvious: a “highlighter” format that is just the original table with stylized editing marks to show changes (and large chunks of unchanged material removed).
For example, here is a highlighter data diff against Jessica Lord’s Hack Spots spreadsheet at the time of writing (Hack Spots is a list of hacking-friendly coffee shops and the like, demoing sheetsee.js):
| @@ | Contributer's Twitter | Name | Address | City | State | long | lat | Country | Wifi Password | Outlets | Couch | Large Table | Brewing | Outdoor Seating | hexcolor |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| cwmma | Block 11 | 11 Bow St | Somerville | MA | -71.096974 | 42.380881 | USA | yes | yes | Intelligentsia | #B9FCFC | ||||
| → | thomaslevine | Bordelands Cafe→Borderlands Café | 870 Valencia St | San Francisco | CA | -122.42151 | 37.759031 | USA | open | yes | ? | ? | coffee | no | #B9FCFC |
| lukekarrys | Cartel Coffee Lab | 225 W University Dr | Tempe | AZ | -111.942978 | 33.421907 | USA | espresso | yes | yes | no | In-house | no | #B9FCFC | |
| thomaslevine | El Beit | 158 Bedford Ave | Brooklyn | NY | -73.956847 | 40.718529 | USA | brooklyn | few | no | no | ? | yes | #B9FCFC | |
| --- | hij1nx | Five Elephant | Reichenberger Straße 101, 10999 | Berlin | Berlin | 13.43829 | 52.493365 | DE | yes | no | no | 5 Elephant | yes | #B9FCFC | |
| uhduh | Gangplank | 260 S Arizona Ave | Chandler | AZ | -111.841302 | 33.244008 | USA | walktheplank | yes | yes | yes | no | #B9FCFC | ||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| sfrdmn | Noisebridge | 2169 Mission St | San Francisco | CA | -122.419161 | 37.762372 | USA | Open | yes | yes | yes | BYOC | possibly | #B9FCFC | |
| +++ | fitzyfitzyfitzy | Sandwich Theory | 590 Valley Rd | Montclair | NJ | -74.208086 | 40.840497 | USA | sandwich | yes | no | coffee | no | yes | #B9FCFC |
This was generated by taking the Hack Spot spreadsheet, editing it
in gnumeric, then comparing with the original using coopyhx.
I corrected a typo, added an entry for Sandwich Theory in my
neighborhood, and - completely accidentally - deleted the
entry for Five Elephant.
Rather than editing the Hack Spots spreadsheet directly in google docs, in my ideal world I’d send a pull-request (and someone would catch my Five Elephant goof).
So far, the diff we have is just row-based. Suppose I also added a column for the location’s website, and deleted the password column (rather missing the whole point) - the highlighter data diff would now look like this:
| ! | +++ | --- | ||||||||||||||
| @@ | Contributer's Twitter | Name | Website | Address | City | State | long | lat | Country | Wifi Password | Outlets | Couch | Large Table | Brewing | Outdoor Seating | hexcolor |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| cwmma | Block 11 | 11 Bow St | Somerville | MA | -71.096974 | 42.380881 | USA | yes | yes | Intelligentsia | #B9FCFC | |||||
| → | thomaslevine | Bordelands Cafe→Borderlands Café | 870 Valencia St | San Francisco | CA | -122.42151 | 37.759031 | USA | open | yes | ? | ? | coffee | no | #B9FCFC | |
| lukekarrys | Cartel Coffee Lab | 225 W University Dr | Tempe | AZ | -111.942978 | 33.421907 | USA | espresso | yes | yes | no | In-house | no | #B9FCFC | ||
| thomaslevine | El Beit | 158 Bedford Ave | Brooklyn | NY | -73.956847 | 40.718529 | USA | brooklyn | few | no | no | ? | yes | #B9FCFC | ||
| --- | hij1nx | Five Elephant | Reichenberger Straße 101, 10999 | Berlin | Berlin | 13.43829 | 52.493365 | DE | yes | no | no | 5 Elephant | yes | #B9FCFC | ||
| uhduh | Gangplank | 260 S Arizona Ave | Chandler | AZ | -111.841302 | 33.244008 | USA | walktheplank | yes | yes | yes | no | #B9FCFC | |||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| sfrdmn | Noisebridge | 2169 Mission St | San Francisco | CA | -122.419161 | 37.762372 | USA | Open | yes | yes | yes | BYOC | possibly | #B9FCFC | ||
| +++ | fitzyfitzyfitzy | Sandwich Theory | www.sandwichtheory.com | 590 Valley Rd | Montclair | NJ | -74.208086 | 40.840497 | USA | yes | no | coffee | no | yes | #B9FCFC |
The highlighter format is tabular, and designed to be as simple as I could make it without introducing ambiguity. The first column in a highlighter diff is called the “action” column, containing marks meaning “inserted row”, “deleted row”, “modified row”, etc. Remaining columns are drawn from either or both of the tables being compared. If there are column differences to note, as there are here, an extra row called the “schema row” is inserted, which has marks for the inserted, deleted, or otherwise modified columns. The whole diff can be transmitted safely in CSV, then optionally formatted for prettiness using some mechanical rules.
There are plenty of other details, but that is the basic flavor of the Coopy highlighter diff format today. You can read more about it or try out two different implementations live, a Javascript implementation and a C++ implementation. You can also get a feel for using this kind of diff in a workflow at GrowRows.com. Please send bug reports, or ideas for better alternatives!
Dealing with conflict
What happens if two people make conflicting changes to a table?
A regular text-based merge would stick in >>>>>>> ======== <<<<<<<
blocks, which would destroy our table’s structure. I’ve played
with a few ways to do better. The method I’m happiest with
so far is to report on conflicts in an extension of the
highlighter diff format that shows the alternate updates
possible. Imagine if, as I fixed the spelling of “Bordelands Cafe”
to “Borderlands Café”,
someone else had already corrected it to
the slightly different “Borderlands Cafe”. So the diff would be:
| @@ | Contributer's Twitter | Name | Address | City | State | long | lat | Country | Wifi Password | Outlets | Couch | Large Table | Brewing | Outdoor Seating | hexcolor |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| cwmma | Block 11 | 11 Bow St | Somerville | MA | -71.096974 | 42.380881 | USA | yes | yes | Intelligentsia | #B9FCFC | ||||
| → | thomaslevine | Bordelands Cafe→Borderlands Cafe→Borderlands Café | 870 Valencia St | San Francisco | CA | -122.42151 | 37.759031 | USA | open | yes | ? | ? | coffee | no | #B9FCFC |
| lukekarrys | Cartel Coffee Lab | 225 W University Dr | Tempe | AZ | -111.942978 | 33.421907 | USA | espresso | yes | yes | no | In-house | no | #B9FCFC | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
Resolving the conflict amounts to just editing the diff, deleting the parts you don’t want and keeping the parts you do. You can get a sense for how this works by testing on http://paulfitz.github.io/coopyhx/. Be sure to select “Use 3-way comparison” option, which will set up two versions of a table with a shared “common ancestor”. Double-click on cells in the diff to view their plain “CSV” representation, and edit them.
Full-blown revision control
I’ve tried two methods to build revision control with all this:
- Modifying
fossil, a distributed revision control system with beautifully compact and hackable source code, to use tabular diffs and merges natively. The result isssfossil(“spreadsheet fossil”) in the Coopy toolbox. - Using custom diff and merge drivers with
git, to achieve a similar result. A tutorial for doing this is at http://share.find.coop/doc/tutorial_git.html.
Both approaches share the same features:
- No change to how the SCM stores data internally. For example,
fossilwill continue using its delta encoding, likewisegit(technically in pack files only). - The visualization of diffs changes, and how merges happen. This is good, since changes that would conflict in text-file world may well not conflict in tabular world, and we are guaranteed to always have valid tables.
Until making more radical changes to the SCM, it definitely makes sense to store tables in a text format. Formats I’ve experimented with are:
- CSV. Simple, globally understood. But just a table.
- CSVS. I made this up. It is an extension to CSV with multiple tables, an unambiguous spot for column names, and a place for table names. Looks like this.
- Sqlitext, pronounced “Sqlite Text”. I made this up. This is a text dump
of an Sqlite database, with consistent ordering of rows. With
careful use of
cleanandsmudgefilters, a “live” Sqlite database can be stored ingit, using this format as an intermediate. This has the nice property of storing more meta-data (keys, references, etc). - SocialCalc. A text format for representing spreadsheets used by SocialCalc and inherited by Audrey Tang’s http://ethercalc.org. Stores table formatting and other good stuff.
Conspicuously absent from this list are common formats like those of Excel. We need one more trick to deal with those.
The last mile
Complicated spreadsheets are not great candidates for version control as I’ve imagined it so far, since we don’t have a way to diff/merge non-data features. So arbitrary spreadsheets in Gnumeric, LibreOffice, and other programs (for simplicity I’m going to call all these programs “Excel” from now on, forgive me) with charts and formulae aren’t really in our scope. But simple spreadsheets, just storing data without anything fancy, can be very useful. And Excel is certainly a convenient, familiar editor for tables.
Putting an Excel file in a git/fossil repository won’t lead anywhere good. But what we can do is this:
- We use git/fossil/… to do version control on data in a version-control-friendly format.
- We keep that data in sync with an Excel file using a merge method that preserves formatting as much as possible. The Excel file is never regenerated from scratch (except parhaps once, on initial cloning), but instead incrementally patched.
In principle a modified SCM could collapse these steps but we’re
definitely not there yet. So what I’ve written is a program called
(perhaps confusingly) Coopy that handles the end-to-end work
of versioning Excel (and similar) files. Here is Coopy cloning
a repository with a single table in it called “numbers” (the user
needed a URL for the repository in order to do this, see the
manual at http://share.find.coop/doc/CoopyGuide.pdf for a complete
workthrough):
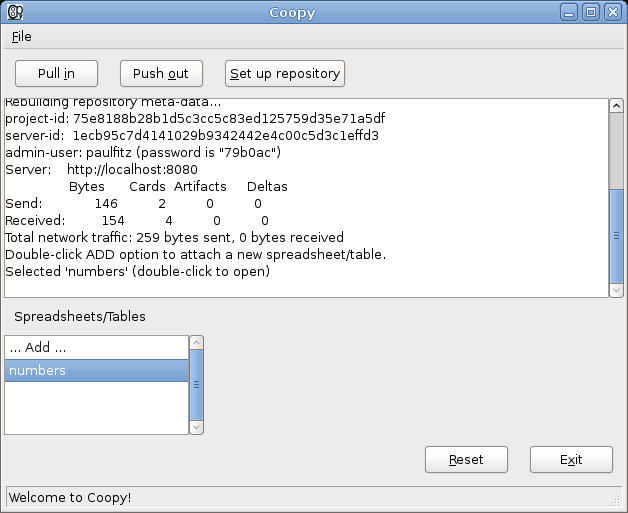
I won’t win any awards for UI design, I know. At this point, under the hood, the repository is checked out on the user’s machine, with data in a neutral format. The list of tables is shown, in this example just a table called “numbers”. When the user selects that table for the very first time, they are prompted to save it:
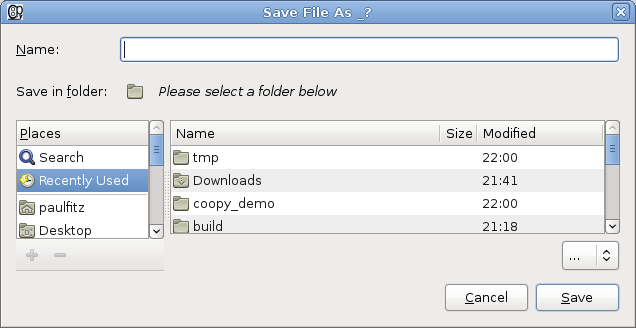
They can choose the format to save the data, for example in
an Excel-compatible format. The appropriate conversion
happens, and the file opens in an appropriate editor (gnumeric for
me):
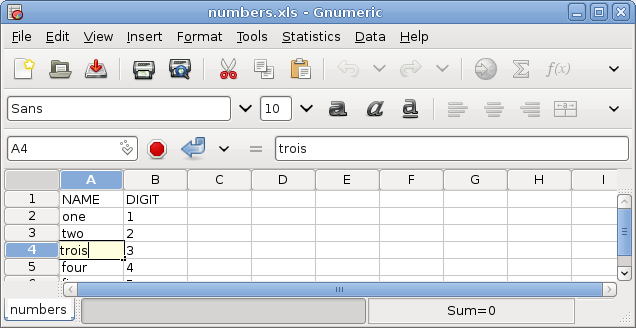
We can now go ahead and edit the table at will. When we’re ready, in Coopy, we click “push out”. We’ll be prompted for a commit message describing the changes, and (the first time) where to actually push to:
From then on, “pulling in” and “pushing out” will act as if they are operating on the spreadsheet, with local formatting being preserved even if no format information is in fact being stored in the neutral repository format. It is perhaps hard to see why that is important, but imagine how annoying it would be if, for example, the column sizes of a spreadsheet kept getting reset everytime you pulled in a collaborator’s changes.
There’s a lot more to say, but a key point is that we could now have one person editing a table in Excel, another in Gnumeric, another tweaking it using Sqlite, and the whole thing being periodically sync’d to a MySQL database on a webserver. Fun!
The power of patching
Stepping back from full-on revision control, I’d like to mention something nice that popped out of this that I hadn’t anticipated. Once you have diff + patch, you can play games like this:
- Store data in some form optimized for machine access, e.g. a MySQL database with carefully chosen keys, indexes, cross-references etc.
- Export part of data to some easy-to-edit form, e.g. a spreadsheet.
- Make changes in the spreadsheet.
- Generate a diff for that spreadsheet.
- Apply that diff as a patch to the original data store e.g. in MySQL.
The export step here will usually blow away all sorts of meta-data vital to the database. It may also scramble stuff due to type mismatches or other muddles. But remember, the patch will get applied with all the original meta-data available, so things work out just fine more often than I expected. I’m excited to push forward on reducing the irreversibility of data exports. Today, as soon as a format conversion happens, fixes to the converted data are much less likely to ever make it back to the original source. This is sad, and can’t be allowed to continue.
Next steps
There’s so much to do it is hard to summarize. And this is all just one piece of the puzzle, for one kind of data (the carefully curated kind listing your neighborhood wifi hotspots, not the gigabyte-per-minute stream from a set of temperature sensors). Here are just some of the things that need doing:
- Nail down the diff format or formats. There are wobbly areas such as column/row reordering. It’d also be exciting to use cross-references between tables when known (e.g. in Sqlite, and maybe Simple Data Format in the future) to produce more meaningful diffs on relational data.
- Support more data formats, more completely. I’ve just been scratching my own random itches so far.
- Get really really solid community-tested implementations of diffing, patching, merging etc.
- Get nice repository hosting in place. In fact,
fossilis interesting for that since it is self-hosting, but it is a bit geeky for non-programmers. I’m hoping to push http://GrowRows.com in this direction. And of course, github works, and would work even better if they supported data diffs. - Think about how systematic data transformations might be
handled better, if they can be handled at all. Personally,
I’m waiting for
dat.
This is all frankly way too much for me. Help!
Appendix: a list of the main Coopy tools
The Coopy toolbox (website, repository, manual) contains the following utilities:
-
ssdiff: Show the difference between two tables/databases/spreadsheets. -
sspatch: Modify a table/database/spreadsheet to apply the changes described in a pre-computed difference. -
ssmerge: Integrate changes in table/database/spreadsheets that have a common ancestor. -
ssresolve: Select a particular resolution to a merge conflict. -
ssformat: Convert tables/databases/spreadsheets from one format to another. -
ssrediff: Convert a diff from one format to another (for example, from highlighter format to a sequence of SQL instructions). -
ssfossil: A lightly modified version offossilto use ssmerge’s 3-way merge algorithm on data. -
Coopy: A first pass at a user interface for versioning Excel and other non-textual formats.
The toolbox is written in C++. Recently I’ve ported some of the core parts of the toolbox to a Javascript (via Haxe) implementation. This port is called coopyhx (website, repository). The reimplementation is better in several respects than the original (need to merge them!), but supports far fewer formats. The port contains:
- The
coopyhxprogram, which is a stripped down version ofssdiffandsspatch, operating only on basic CSV/JSON tables and the highlighter diff format. - A javascript library for diffing and patching, suitable for in-browser use.
- A render function for converting highlighter diffs in CSV format into pretty HTML.
- A render function for handsontable to allow online editing of diffs in a pretty format.
Awkwardly, there’s also an entirely separate ruby implementation (source, gem), strictly limited to Sqlite, that was written for use on ScraperWiki (classic).
Related websites:
-
http://growrows.com, a start at a service for crowd-sourcing tables, using diffs and patches (without calling them that).
-
http://datacommons.find.coop/vision, the Data Commons Co-op, incorporated in July 2012 in Massachusetts. The co-op has 20 member organizations, mostly in the US, a couple in Canada, plus one recently in the UK. This co-op specializes in archiving, correlating, and disseminating data about alternative economic activity, and needs lots of software that doesn’t quite exist yet!
 We make tools, apps and insights using
open stuff
We make tools, apps and insights using
open stuff


Comments