
Using Data Packages with R
R is a popular open-source programming language and platform for data analysis. Frictionless Data is an Open Knowledge International project aimed at making it easy to publish and load high-quality data into tools like R through the creation of a standard wrapper format called the Data Package.
In this post, I will demonstrate an in-progress version of
datapkg, an R package that makes it easy to load Data Packages
into your R environment by automating otherwise manual import steps
using information provided in the Data Package descriptor file
datapackage.json. datapkg was developed through a collaboration
between Open Knowledge International and rOpenSci,
an organization that specializes in creating open-source tools using R
for advancing open science.
Loading Tabular Data in R

R’s core strengths as a data analysis framework lie in its support for a wide array of statistical tests, its straightforward, powerful options for static visualization, and the ease with which its functionality can be extended. For these reasons, R enjoys a vibrant online community who contribute daily to thousands of packages on CRAN. For this post, we will avoid going deep into what makes R so powerful, and instead focus on the typical first step in any data analysis project: loading source data. This post assumes you have a fairly basic understanding of R and a working R environment on your machine.
When loading tabular data from a file into an R environment, it is
common to use the functions read.csv or read.delim. These are
wrappers for the more generic read.table function that provide sane
defaults for reading from commonly formatted
CSV and tab-delimited files,
respectively. These commands read data into what’s called a “data
frame”, R’s basic data structure for storing data tables. In this
structure, each column (“vector”) in the original tabular data file
may be assigned a different type (e.g. string, integer, date).
As a simple example, let’s load a CSV file containing the
CBOE Volatility Index using read.csv(). This dataset can be
found on our example Data Packages repo in
the subdirectory “finance-vix”. Once downloaded, we can set R’s
working directory to where the data is stored and take a peek at the
files within its data subdirectory:
setwd('/Users/dan/Downloads/example-data-packages-master/finance-vix')
list.files("data")'vix-daily.csv'
We can read this single CSV, vix-daily, using R’s read.csv()
function and assign its output to a data frame called
volatility_raw. Afterwards, we can get a sample of the data by
viewing the first few rows of the file using the head() function.
volatility_raw <- read.csv("data/vix-daily.csv")
head(volatility_raw)| Date | VIXOpen | VIXHigh | VIXLow | VIXClose | |
|---|---|---|---|---|---|
| 1 | 1/2/2004 | 17.96 | 18.68 | 17.54 | 18.22 |
| 2 | 1/5/2004 | 18.45 | 18.49 | 17.44 | 17.49 |
| 3 | 1/6/2004 | 17.66 | 17.67 | 16.19 | 16.73 |
| 4 | 1/7/2004 | 16.72 | 16.75 | 15.5 | 15.5 |
| 5 | 1/8/2004 | 15.42 | 15.68 | 15.32 | 15.61 |
| 6 | 1/9/2004 | 16.15 | 16.88 | 15.57 | 16.75 |
In the process of loading this data into a data frame, R made an
educated guess as to the types of data found in each column. We can
display those types by looking at the the “structure” of an R object
using the str command.
str(volatility_raw)'data.frame': 3122 obs. of 5 variables:
$ Date : Factor w/ 3122 levels "01/02/2014","01/02/2015",..: 543 644 652 659 666 672 493 501 508 515 ...
$ VIXOpen : num 18 18.4 17.7 16.7 15.4 ...
$ VIXHigh : num 18.7 18.5 17.7 16.8 15.7 ...
$ VIXLow : num 17.5 17.4 16.2 15.5 15.3 ...
$ VIXClose: num 18.2 17.5 16.7 15.5 15.6 ...
We can see that while R has correctly guessed the types of “VIXOpen”,
“VIXHigh”, “VIXLow”, and “VIXClose” to be num, it has incorrectly
guessed the type of the “Date” to be Factor when R has a much more
appropriate type for the kind of data in this column called,
predictably, Date. This is a problem easily demonstrable by
attempting to plot the data.
plot(volatility_raw$Date, volatility_raw$VIXOpen, type='l')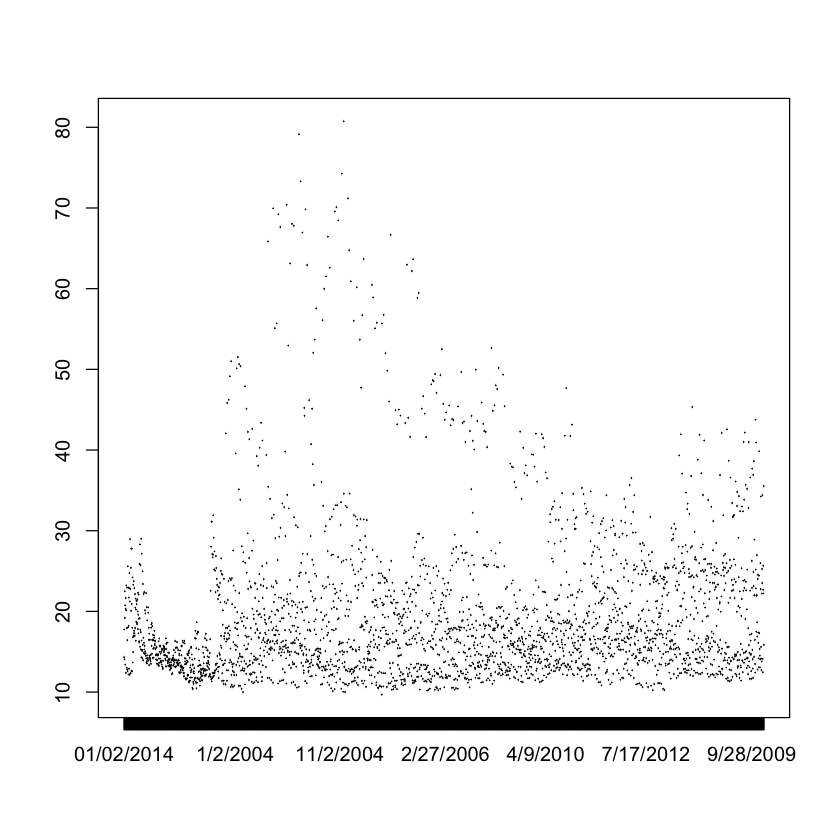
What should be the steadily increasing Date on the X axis is, instead,
out of order because the Date column is has not been assigned its
correct type. In this very simple case, there is a straightforward
fix which is to manually re-assign the Date column (in our data frame
represented as volatility_raw$Date) to a type Date passing the
special format %m/%d/%Y which we found out by previewing the data.
After this, we can revisit its structure using the str() command.
volatility_raw$Date <- as.Date(volatility_raw$Date, "%m/%d/%Y")
str(volatility_raw)'data.frame': 3122 obs. of 5 variables:
$ Date : Date, format: "2004-01-02" "2004-01-05" ...
$ VIXOpen : num 18 18.4 17.7 16.7 15.4 ...
$ VIXHigh : num 18.7 18.5 17.7 16.8 15.7 ...
$ VIXLow : num 17.5 17.4 16.2 15.5 15.3 ...
$ VIXClose: num 18.2 17.5 16.7 15.5 15.6 ...
We have successfully given the Date column a Date type, and we
should be able to run the same plot() function above and get a
better result. While this is a good solution for this single dataset
with a single incorrectly guessed column, it doesn’t scale well to
multiple incorrectly guessed columns across multiple datasets. In
addition, it only represents one type of manual task to be performed
on a new set of data. We have designed the Data Package format to
obviate this, and other kinds of tedious “data wrangling” tasks. In
the next section, we will perform the same task above using the
datapkg library.
Loading Tabular Data Packages in R
A Data Package is a specification for creating a
“container” for transporting data by saving useful
metadata in a specially formatted file. This file is called
datapackage.json, and it is stored in the root of a directory
containing a given dataset. When loading a Data Package,
datapkg—the new R Data Package library developed by
rOpenSci—reads this extra metadata in order to
conveniently load high quality, well formatted data into your R
environment.
Installing datapkg
Note: the Data Package library for R is still in testing and subject to change. For this reason, it is not yet on CRAN and must be installed from its GitHub repository using the devtools package.
To install, start your R environment and run the following commands:
install.packages("devtools")
library(devtools)
install_github("hadley/readr")
install_github("ropenscilabs/jsonvalidate")
install_github("frictionlessdata/datapackage-r")Reading Data
Revisiting our data directory, we can examine the files in the root
using the list.files() function:
'data' 'datapackage.json'
The presence of the datapackage.json file indicates our current R
working directory is points to a Data Package, so we can load the
datapkg library and use the datapkg_read() function to read our
Data Package (note: we can also pass a path or URL to this function).
library(datapkg)
volatility <- datapkg_read()The datapkg_read() function reads not only the data in the dataset,
but also the metadata stored with it. This metadata includes high
level information like the author, source, and license of the dataset.
We can inspect this information by reading various variables stored on
this object. For instance, to get a fuller, human-readable title, we
can access volatility$title or, if the Data Package has a “homepage”
variable set, we can access it using volatility$homepage.
'VIX - CBOE Volatility Index'
'http://www.cboe.com/micro/VIX/'
datapkg_read() also uses schema information stored in the
datapackage.json to facilitate the loading of data. As shown above,
one misstep we encountered when loading a new dataset into R was
neglecting to correct an incorrectly guessed column type. What the
Data Package format provides is a simple, standard way to store that
information with a dataset to automate this and other steps. The
following snippet shows how the datapackage.json descibes this
information:
"schema": {
"fields": [
{
"name": "Date",
"type": "date",
"format": "fmt:%m/%d/%Y"
},
{
"name": "VIXOpen",
"type": "number"
},
{
"name": "VIXHigh",
"type": "number"
},
{
"name": "VIXLow",
"type": "number"
},
{
"name": "VIXClose",
"type": "number"
}
]
}As above, we can verify that datapkg_read() used this information to
construct its data frame by calling the str() function. The data
variable on the volatility object created by datapkg_read() points
to a list of files (“resources”) on the dataset; vix-daily is the
name of the resource—expressed as a data frame—we want.
str(volatility$data$`vix-daily`)Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 3122 obs. of 5 variables:
$ Date : Date, format: "2004-01-02" "2004-01-05" ...
$ VIXOpen : num 18 18.4 17.7 16.7 15.4 ...
$ VIXHigh : num 18.7 18.5 17.7 16.8 15.7 ...
$ VIXLow : num 17.5 17.4 16.2 15.5 15.3 ...
$ VIXClose: num 18.2 17.5 16.7 15.5 15.6 ...
The output shows that the Date column has been set with the correct type. Because the type on the Date column has been set correctly, we can immediately plot the data.
vix.daily <- volatility$data$`vix-daily`
plot(vix.daily$Date, vix.daily$VIXOpen, type='l')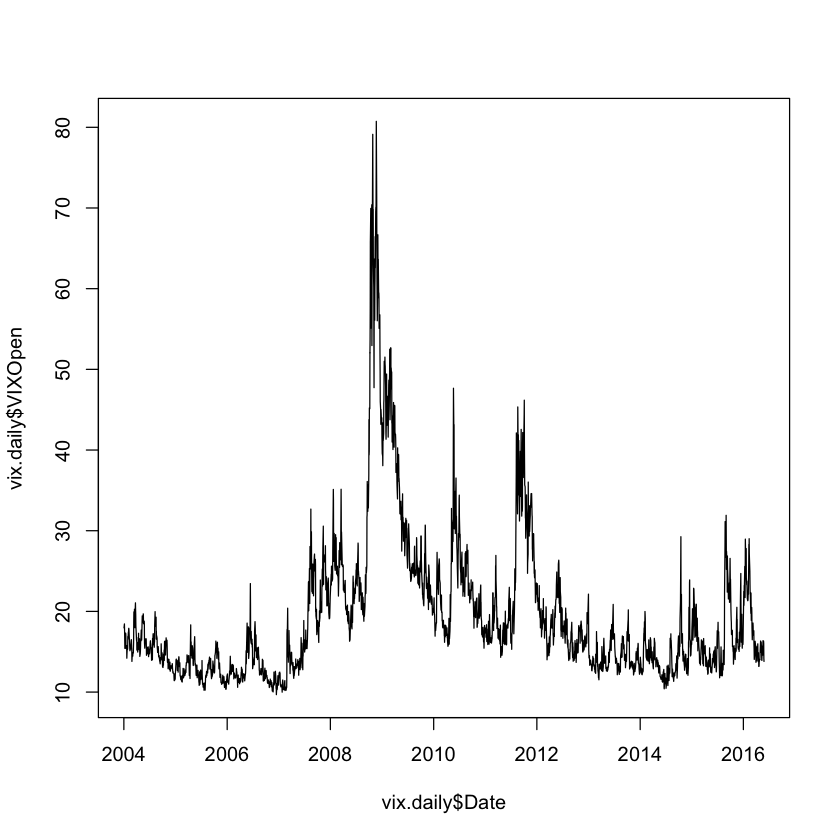
Going Forward
This has been a very small example of the basic functionality of the R library. This software is still in testing, so if you are an R user and would like to use Data Packages to help manage your data in R, please let us know. You can leave a comment here on the forum.
To see the code used in this post, visit its Jupyter Notebook.
 We make tools, apps and insights using
open stuff
Join in »
We make tools, apps and insights using
open stuff
Join in »
 Follow @okfnlabs
Follow @okfnlabs

Comments