Core Data on DataHub.io
This blog post was originally published on datahub.io by Rufus Pollock, Meiran Zhiyenbayev & Anuar Ustayev.
The “Core Data” project provides essential data for the data wranglers and data science community. Its online home is on the DataHub:
https://datahub.io/docs/core-data
This post introduces you to the Core Data, presents a couple of examples and shows you how you can access and use core data easily from your own tools and systems including R, Python, Pandas and more.
Why Core Data
If you build data driven applications or data driven insight you regularly find yourself wanting common “core” data, things like lists of countries, populations, geographic boundaries and more.
However, finding good quality data has always been challenging. Professionals can spend lots of time finding and preparing data before they get to do any real work analysing or presenting it.
To address this, a few years ago we started the “core data” project as part of the Frictionless Data initiative. Its purpose was to curate important, commonly used datasets including reference data like country codes, indicators like population and GDP, and geodata like country boundaries. It provides them in a high-quality, easy-to-use, and standard form.
Recently the Core Data project has got even better with a new home on the newly upgraded DataHub and has expanded thanks to new partners like Datopian and John Snow Labs (more on this in a future post!).
Examples
There are dozens of core datasets already available and many more being worked on, including a list of countries and their 2 digit codes, and a more extensive version.
List of Countries
Ever needed to build a drop-down list of countries in a web application? Or ever needed to add country name labels for a graph and only had country codes?
Then these datasets are for you!
First up is the very simple “country-list” dataset:
https://datahub.io/core/country-list
You can see a preview table for the dataset on the showcase page:
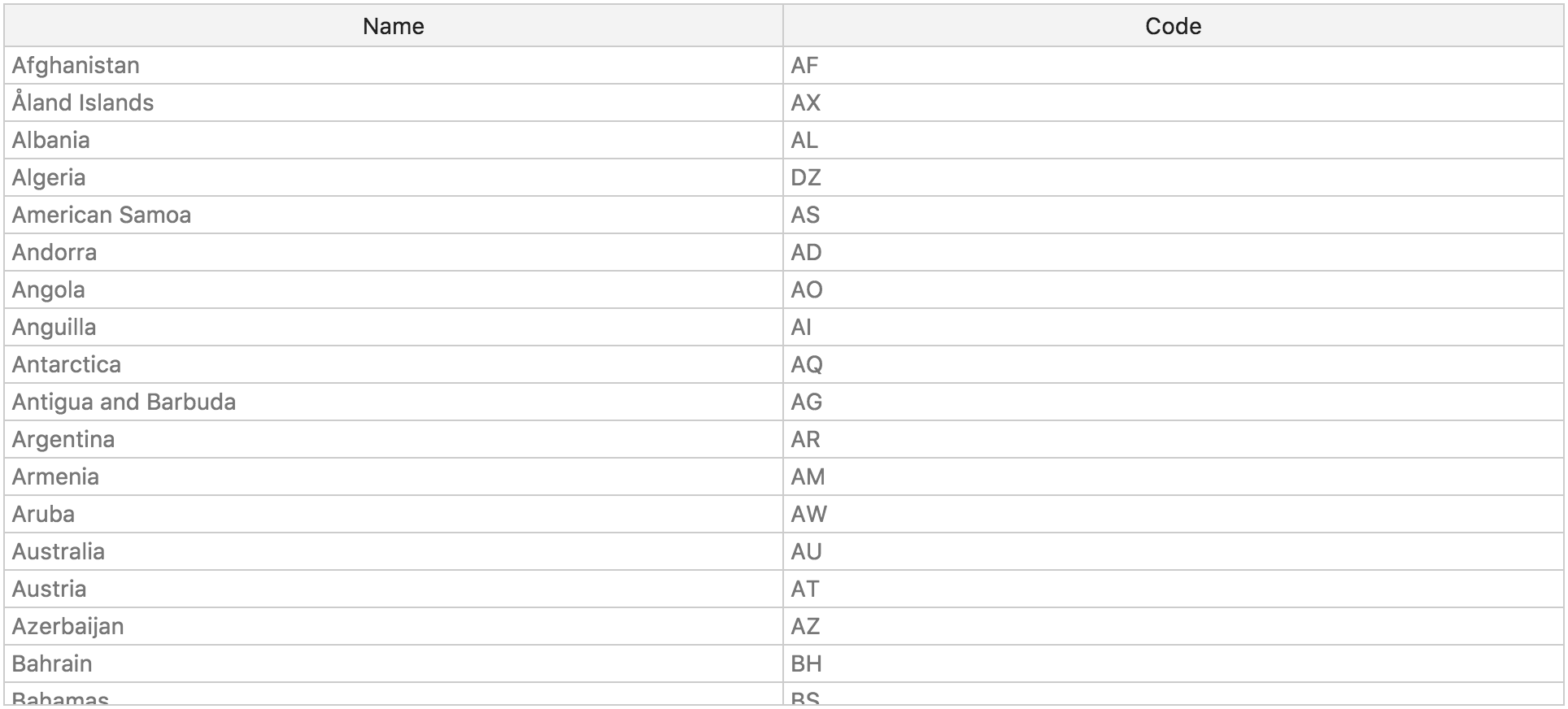
You can download it in either CSV or JSON formats:

- CSV: https://datahub.io/core/country-list/r/data.csv
- JSON: https://datahub.io/core/country-list/r/data.json
Country Codes
Maybe the simple list of countries is not enough for you. Perhaps you need phone codes for each country, or want to know their currencies?
We’ve got you covered with the more extensive country codes dataset:
https://datahub.io/core/country-codes
All the countries from Country List including number of associated codes - ISO 3166 codes, ITU dialing codes, ISO 4217 currency codes, and many others. This dataset includes 26 different codes and associated information.
You can also preview the data and download in different formats just like it is described for Country List dataset above:
- CSV: https://datahub.io/core/country-codes/r/country-codes.csv
- JSON: https://datahub.io/core/country-codes/r/country-codes.json
Population
This is another useful dataset for people: you regularly need population in order to do normalisations and calculate per capita figures as part of a statistical analysis.
This dataset includes population figures for countries, regions (e.g. Asia) and the world. Data comes originally from World Bank and has been converted into standard tabular data package with CSV data and a table schema:
https://datahub.io/core/population
Preview the data on the showcase page:
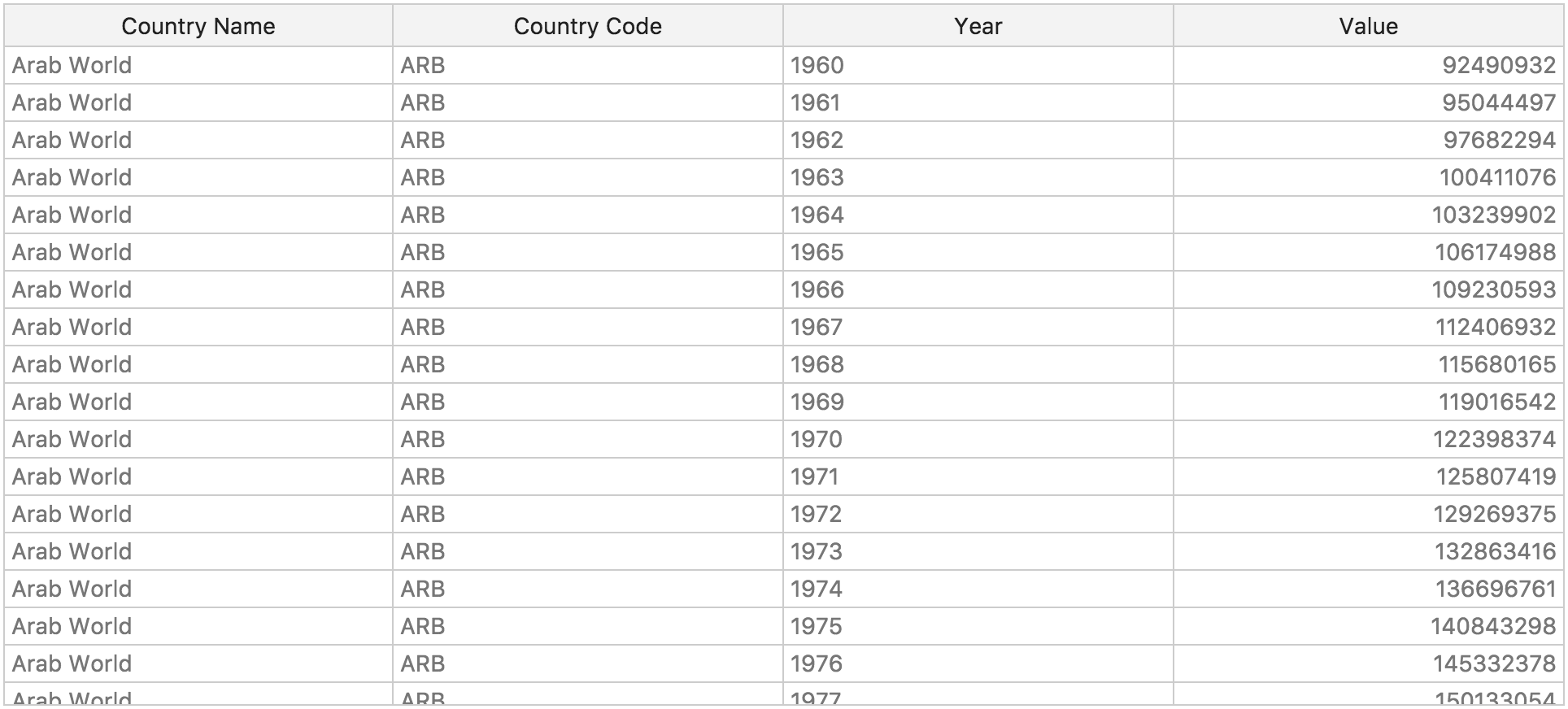
Get the data in CSV or JSON formats just like for any other Core Datasets:
- CSV: https://datahub.io/core/population/r/population.csv
- JSON: https://datahub.io/core/population/r/population.json
Use Core Data from your favorite language or tool
We have made Core Data easy-to-use from various programming languages and tools. We will walk through using our Country List example. But you can apply these instructions to any other Core Data in the DataHub.
CSV and JSON
If you just need to get data, you have a direct link usable from any tool or app e.g. for the country list:
- CSV - https://datahub.io/core/country-list/r/data.csv
- JSON - https://datahub.io/core/country-list/r/data.json
cURL
Following commands help you to get the data using “cURL” tool. Use -L flag so “cURL” follows redirects:
# Get the data:
curl -L https://datahub.io/core/country-list/r/data.csv
# datapackage.json provides metadata and a list of all data files
curl -L https://datahub.io/core/country-list/datapackage.json
# See just the available data files (resources):
curl -L https://datahub.io/core/country-list/datapackage.json | jq ".resources"R
If you are using R here’s how to get the data you want quickly loaded:
install.packages("jsonlite")
library("jsonlite")
json_file <- "https://datahub.io/core/country-list/datapackage.json"
json_data <- fromJSON(paste(readLines(json_file), collapse=""))
# access csv file by the index starting from 1
path_to_file = json_data$resources[[1]]$path
data <- read.csv(url(path_to_file))
print(data)Python
Here we take a look at how to get Country List in Python programming language:
For Python, first install the datapackage library (all the datasets on DataHub are Data Packages):
pip install datapackageAgain, we’ll use the country-list dataset:
from datapackage import Package
package = Package('https://datahub.io/core/country-list/datapackage.json')
# get list of resources:
resources = package.descriptor['resources']
resourceList = [resources[x]['name'] for x in range(0, len(resources))]
print(resourceList)
data = package.resources[0].read()
print(data)Pandas
In order to work with Data Packages in Pandas you need to install the Frictionless Data data package library and the pandas extension:
pip install datapackage
pip install jsontableschema-pandasTo get the data run following code:
import datapackage
data_url = "https://datahub.io/core/country-list/datapackage.json"
# to load Data Package into storage
storage = datapackage.push_datapackage(data_url, 'pandas')
# data frames available (corresponding to data files in original dataset)
storage.buckets
# you can access datasets inside storage, e.g. the first one:
storage[storage.buckets[0]]Ruby, JavaScript and many more
We also have support for JavaScript, SQL, Ruby and PHP. See our “Getting Data” tutorial for more:
https://datahub.io/docs/getting-started/getting-data
Conclusion
This post has shown how you can import datasets in a high quality, standard form quickly and easily.
There are many more datasets to explore than the three we showed you here. You can find a full list here:
Finally, we would love collaborators to help us curate even more core datasets. If you’re interested you can find out more about the Core Data Curator program here:
https://datahub.io/docs/core-data/curators
If you have questions, comments or feedback join DataHub’s chat channel or open an issue on DataHub’s tracker.
 We make tools, apps and insights using
open stuff
Join in »
We make tools, apps and insights using
open stuff
Join in »
 Follow @okfnlabs
Follow @okfnlabs

Comments