Introduction to OLAP
What is OLAP?
“Online Analytical Processing – OLAP is an approach to answering multi-dimensional analytical queries swiftly” says Wikipedia. What does that mean? What are multi-dimensional analytical queries? Why this approach? We will learn all this in a short blog series.
The term OLAP is becoming a bit less appropriate. The OLAP term comes from traditional data warehousing from times when “big data” would fit into your current laptop and it was time consuming to process even that little amount compared to today’s standards. Nowadays the majority of analytical processing can be considered online. More appropriate term is “multidimensional data processing” as we will see later. For now we will stick with the original name of the approach.
The basic concepts of OLAP are:
- data cubes – multi-dimensional approach to data
- fast aggregation or pre-aggregation
Why OLAP?
There are two sides of data: data to be used by application systems (transactional, operational) and data to be used by humans for decision making. The two kinds of data are in many cases very different, as the applications have other needs than humans do.
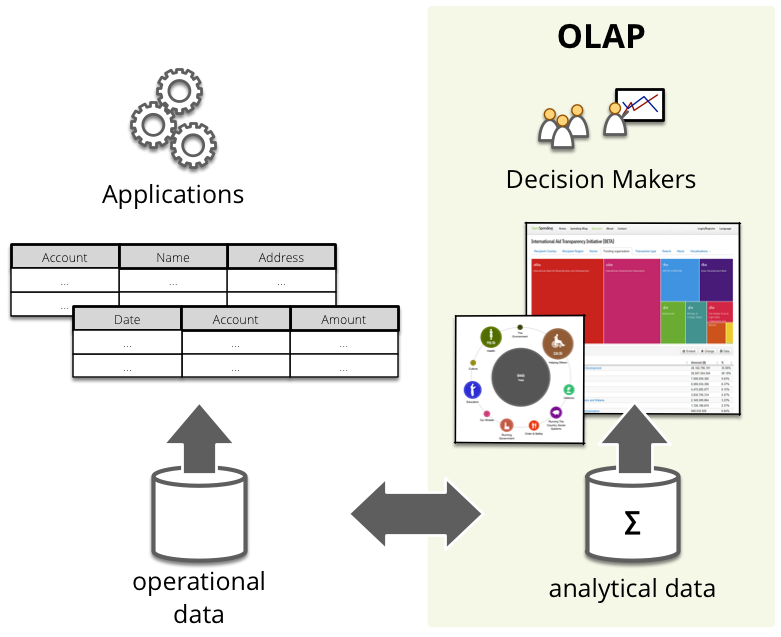
Applications require and store more detailed data. They require efficiency on transaction (operation) level and integrity for example. The data might be stored in different places, depending on how they are used by the systems. On the other hand, decision makers want to see the data at one place and in the form that reflects their view on the world. They don’t care how long does it take to store a million transactions, they want to know when those million transactions happened and where.
Why OLAP then? Decision makers, analysts or just any other curious people would like to answer their questions quickly. The data in database systems are not stored in a way that the questions can be answered easily. OLAP is the technical and semantic bridge between the two ways of using the data.
Why can an OLAP system answer the analytical queries swiftly or at least faster than operational system? The data in the analytical system are already modeled and prepared in a form closer to the typical questions:
Pre-aggregation – data are aggregated at different levels of granularity, such as monthly data, and stored. Questions like “what were the sales in January 2010” would not require any computation, just direct fetch of the answer. The data might be pre-aggregated at all levels and combinations of their properties (dimensions).
Multi-dimensional databases – data are stored in alternative kinds of faster structures.
Different Approach
In operational systems update of information is permitted even required. Keeping change history might be impractical in events with high frequency. From analytical point of view this might be undesired, as we would like to know historical evolution of a state. For example: it is sufficient to know actual account amount in the bank or available budget of a kind, analysts would like to see how the amount changed over time, how it might have been influenced by other events.
One of the differences that I consider crucial are the system requirements: for operational systems the requirements for data design are well known up in front. It is very unlikely that an application will generate an unexpected query to the system, therefore the system is built around the application’s behavior. On the other hand, requirements of an analysts are ad-hoc. The analytical system has to be designed in a way that would allow quick answers to business questions.
Redundancy: in applications redundancy might introduce quite lot of errors mostly because of data inconsistency. In the analytical system the redundancy is many times desired. Any information that is readily available close to the data being queried is making the responses faster. The design of the analytical systems and presence of historical data allows reconstructability of the redundant information, therefore any inconsistencies might be corrected. Examples of redundancies in the analytical systems:
- multiple copies of the same data in different contexts
- denormalized data
One more difference I am going to mention here is the amount of data being processed at a single time. In the operational systems only small amount of data is required to complete desired operation. For example: change of client’s address (client’s identification and new address), budget expense (budget line and the expended amount). In the analytical system large amount of data has to be “touched” to answer analysts question: “what was the spending by country?”
Here are the differences between analytical vs. operational data summarized:
- subject oriented vs. application oriented
- summarized vs. detailed
- analysis driven vs. transaction driven
- read-only vs. updateable
- unknown processing requirements vs. well known processing requirements
- redundancy allowed vs. redundancy undesired
- large amount of data per operation vs. tiny amount of data per operation
The two systems can be physically separate, but with modern tools the analytical system might be integrated in a database platform with transactional.
Software
There are many commercial databases and applications for multi-dimensional data modelling and OLAP in form of Business Intelligence suites from historically big names such as Oracle, Microsoft, SAS and others. Google for “OLAP documentation” and company name to get the idea about their approach, capabilities and features.
New trend is to have OLAP or OLAP-like systems as a service, were one imports his data, the software transforms the data into data cubes and provides reporting interface.
There are very few open-source OLAP packages though and even fewer general-purpose. Just to mention two:
- Cubes – light-weigh OLAP framework (written in Python, Github)
- Pentaho – full-featured Business Intelligence suite (written in Java)
Summary
OLAP is a way of making transactional data usable and understandable for decision making.
Further reading:
Next time we will look at the multi-dimensional modeling.
 We make tools, apps and insights using
open stuff
We make tools, apps and insights using
open stuff


Comments