

The Data Wrangling Blog
-
After 6 years at Google, Daniel Fireman is currently a Ph.D. student, professor and activist for government transparency and accountability in the Northeast of Brazil. He was one of the 2017’s Frictionless Data Tool Fund grantees and implemented the core Frictionless Data specification in the...
-
Today we’re releasing a major version for datapackage-pipelines, version 2.0.0. This new version marks a big step forward in realizing the Data Factory concept and framework. We integrated datapackage-pipelines with its younger sister dataflows, and created a set of common building blocks you can now...
-
Data Factory is an open framework for building and running lightweight data processing workflows quickly and easily. We recommend reading this introductory blogpost to gain a better understanding of underlying Data Factory concepts before diving into the tutorial below. Learn how to write your own...
-
Today I’d like to introduce a new library we’ve been working on - dataflows. DataFlows is a part of a larger conceptual framework for data processing. We call it ‘Data Factory’ - an open framework for building and running lightweight data processing workflows quickly and...
-
Matt Thompson was one of 2017’s Frictionless Data Tool Fund grantees tasked with extending implementation of core Frictionless Data data package and table schema libraries in Clojure programming language. You can read more about this in his grantee profile. In this post, Thompson will show...
-
Georges Labrèche was one of 2017’s Frictionless Data Tool Fund grantees tasked with extending implementation of core Frictionless Data libraries in Java programming language. You can read more about this in his grantee profile. In this post, Labrèche will show you how to install and...
-
On March 3, communities around the world marked Open Data Day in over 400 events. Here’s the dataset for all Open Data Day 2018 events. In this post, we will harvest Open Data Day affiliated content from Twitter and analyze it using R before packaging...
-
Daniel Fireman was one of 2017’s Frictionless Data Tool Fund grantees tasked with extending implementation of core Frictionless Data libraries in Go programming language. You can read more about this in his grantee profile. In this post, Fireman will show you how to install and...
-
This document outlines a simple design pattern for a “core” data library "data". The pattern is focused on access and use of: individual files (streams) collections of files (“datasets”) Its primary operation is open: file = open('path/to/file.csv') dataset = open('path/to/files/') It defines a standardized “stream-plus-metadata”...
-
Open Knowledge Greece was one of 2017’s Frictionless Data Tool Fund grantees tasked with extending implementation of core Frictionless Data libraries in R programming language. You can read more about this in their grantee profile. In this post, Kleanthis Koupidis, a Data Scientist and Statistician...
-
The Data Package Creator, create.frictionlessdata.io, is a revamp of the Data Packagist app that lets you create and edit and validate your data packages with ease. Read on and find out how. Frictionless Data aims to make it effortless to transport high quality data among...
-
datapackage-pipelines is a framework for defining data processing steps to generate self-describing Data Packages, built on the concepts and tooling of the Frictionless Data project. You can read more about datapackage-pipelines in this introductory post. Data wrangling can be quite a tedious task - We...
-
When it comes to tabular data, the Frictionless Data specifications provide users with strong conventions for declaring both the shape of data (via schemas) and information about the data (as metadata on package and resource descriptors). Within the Frictionless Data world, we purposefully refer to...
-
We have to deal with many challenges when scraping a page. What’s the page’s layout? How do I extract the bits of data I want? How do I know when their layout changes and break my code? How can I be sure that my code...
-
This blog post was originally published on datahub.io by Rufus Pollock, Meiran Zhiyenbayev & Anuar Ustayev. The “Core Data” project provides essential data for the data wranglers and data science community. Its online home is on the DataHub: https://datahub.io/core https://datahub.io/docs/core-data This post introduces you to...
-
This post walks you through the major changes in the Data Package v1 specs compared to pre-v1. It covers changes in the full suite of Data Package specifications including Data Resources and Table Schema. It is particularly valuable if: you were using Data Packages pre...
-
The Frictionless Data team released v1 specifications in the first week of September 2017 and Paul Walsh, Chief Product Officer at Open Knowledge International, wrote a detailed blogpost about it. With this milestone, in addition to modifications on pre-existing specifications like Table Schema1 and CSV...
-
In his Open Knowledge International Tech Talk, Developer Brook Elgie describes how we are using Data Package Pipelines and Redash to gain insight into our organization in a declarative, reproducible, and easy to modify way. This post briefly introduces a newly launched internal project at...
-
This blog was originally posted on the Publish What You Fund website. Maintained, machine readable versions of the DAC and CRS code lists are now available as CSV and JSON! Here’s how Publish What You Fund and Open Knowledge made it happen… The OECD’s Development...
-
Information is everywhere. This means that there is so much we need to know at any given time, but such limited capacity and time to internalize it all. True art, therefore, lies in the ability to draw summaries adequate enough to save time and impart...
-
datapackage-pipelines is the newest part of the Frictionless Data toolchain. Originally developed through work on OpenSpending, it is a framework for defining data processing steps to generate self-describing Data Packages. OpenSpending is an open database for uploading fiscal data for countries or municipalities to better...
-
For our Frictionless Data project, we were curious to learn about some of the common issues users face when working with data. To that end, we started a Case Study series to highlight projects and organizations working with the Frictionless Data specifications and tooling in...
-
Last month, we had the first call of the Frictionless Data Specifications Working Group, starting a new chapter in the project. The call covered the status of the specifications to date, current adoption, upcoming technical pilots and partnerships, and how work will be organized going...
-
For the last 15 months the Open Knowledge Foundation Germany has been working on a prototype to monitor progress towards the sustainable development goals (SDGs) from an independent, civil society-led perspective. There’s a detailed blog post on why such independent monitoring is necessary at our...
-
Having co-organized csv,conf,v2 this past May, a few of us from Open Knowledge International had the awesome opportunity to travel to Berlin and sit in on a range of fascinating talks on the current state-of-the-art on wrangling messy data. Previously, I posted about Comma Chameleon...
-
Frictionless Data is about making it effortless to transport high quality data among different tools and platforms for further analysis. We obviously ♥ data science, and pandas is one of the most popular Python libraries for advanced data analysis and modeling. This post highlights our...
-
Back in March, I wrote about a CKAN extension for publishing and exporting Data Packages1. This extension, datapackager, has been updated and is now live on our very own CKAN instance, DataHub. DataHub users can now import and export Data Packages via the CKAN UI...
-
Having co-organized csv,conf,v2 this past May, a few of us from Open Knowledge International had the awesome opportunity to travel to Berlin and sit in on a range of fascinating talks on the current state-of-the-art on wrangling messy data. One such talk was given by...
-
R is a popular open-source programming language and platform for data analysis. Frictionless Data is an Open Knowledge International project aimed at making it easy to publish and load high-quality data into tools like R through the creation of a standard wrapper format called the...
-
When storing your data in Data Packages, it is considered good practice to store scripts for updating, processing, or analyzing your data in a directory called scripts/ placed at the root of your Data Package. I’ve written a tutorial to show how to achieve continuous...
-
Much of the open data on the web is published in CSV or Excel format. Unfortunately, it is often messy and can require significant manipulation to actually be usable. In this post, I walk through a workflow for automating data validation on every update to...
-
Extracting data from PDFs remains, unfortunately, a common data wrangling task. This post reviews various tools and services for doing this with a focus on free (and preferably) open source options. The tools we can consider fall into three categories: Extracting text from PDF Extracting...
-
When crafting data from some other data, like packaging public data, using the good tools can really ease development process and reliability of the data. The venerable make which have already been used for decades to build software, is a very good option as advocated...
-
Tool and platform integrations for “Data Packages” are key elements of our Frictionless Data Initiative at Open Knowledge International. We recently posted on the main blog about some integration work funded by our friends at Google. We’ve built useful Python libraries for working with Tabular...
-
The first quarter of 2016 is almost through, which means that the OKFN Labs Newsletter is on its way! But we have a problem. We know that you have spent the last 3 months writing awesome code, founding disruptive new projects and basically changing the...
-
Hey there hackers & hackettes! Welcome to the 4th quarter 2015 Open Knowledge Labs Newsletter: A Very Special Holiday Edition of the Open Knowledge Labs Newsletter. We hope that all of our readers, volunteers, team members & contributors have a great holiday season. Labs is...
-
Welcome to the second Labs Newsletter of 2015! There has been excellent progress on various open data tools and initiatives across the Open Knowledge network since the last newsletter. Let’s take a look: Labs Still <3 Discourse Open Knowledge is in the process of centralizing...
-
As software developers, we are always looking for data to solve a problem or address a shortcoming. It’s just how we’re wired. So, you heard of open data [1], and now you’re excited to go exploring and get the open data needed for the project....
-
Give Me Text! In a previous post, I detailed a web service where you can throw documents of many kinds at it, and get text in return. We’ve now given this service a name, “Give Me Text!”, and a nice URL at http://givemetext.okfnlabs.org/ for both...
-
The Health and Social Care Information Centre (HSCIC) is responsible for publishing a large proportion of the official statistics related to health and care in England. Each year we release about 250 statistical publications, ranging from high-level summary data on hospital admissions, through to detail...
-
Are you in need of a clean, well maintained list of all countries and their associated international codes in CSV and JSON? If so, you might consider the country-codes and country-list data packages available at data.okfn.org. Country Codes, using source data from ISO, the CIA...
-
Welcome to the first Labs Newsletter of 2015! There has been some great activity around open data and tech in the Open Knowledge network over the first quarter of 2015. Let’s dive straight in! Labs <3 Discourse In case you don’t know, Discourse is an...
-
Tabular data packages are a pragmatic way of both publishing your own data and consuming the data that others share with the world. The newly published datapak is a Ruby library that lets you work with tabular data packages using ActiveRecord and, thus, your SQL...
-
Introducing the Good Tables web service Good Tables is a free online service that helps you find out if your tabular data is actually good to use - it can check for structural problems (blank rows and columns) as well as ensure that data fits...
-
Getting text out of documents Last year I was working on beta.offenedaten.de, a catalog of data catalogs in Germany using the CKAN platform as the basis. Although the topic of how to enable full-text search of documents in CKAN data catalogs is somewhat open, I...
-
What is it? Good Tables is a Python package for validating tabular data through a processing pipeline. It is built by Open Knowledge, with funding from the Open Data User Group. Good Tables is currently an alpha release. Applications range from simple validation checks on...
-
Wanted: volunteers to join a team of “Data Curators” maintaining “core” datasets (like GDP or ISO-codes) in high-quality, easy-to-use and open form. What is the project about: Collecting and maintaining important and commonly-used (“core”) datasets in high-quality, standardized and easy-to-use form - in particular, as...
-
dpm the command-line ‘data package manager’ now supports pushing (Tabular) Data Packages straight into a CKAN instance (including pushing all the data into the CKAN DataStore): dpm ckan {ckan-instance-url} This allows you, in seconds, to get a fully-featured web data API – including JSON and...
-
Introduction and ETL The abbreviation ETL stands for extract, transform and load. What is it good for? For everything between data sources and fancy visualisations. In the data warehouse the data will spend most of the time going through some kind of ETL, before they...
-
This post explains our issues at the Portuguese open data front when it comes to providing bulk datasets in standard and easy-to-parse ways. It also introduces Data Central, our tentative solution to those issues: a Python tool to generate static web frontends for your data...
-
Welcome back to the OKFN Labs! Members of the Labs have been building tools, visualizations, and even new data protocols—as well as setting up conferences and events. Read on to learn more. If you’d like to suggest a piece of news for next month’s newsletter,...
-
At the first International Sports Hackdays in Basel, Sierre and Milan, over 120 developers and designers, journalists and scientists, professionals and amateurs came together to prototype new approaches to make creative use of sports data. They built new types of hardware, new interfaces for fitness...
-
Football is the world’s most popular sport and the World Cup in Brazil - kicking off next month in São Paulo on June 12th (in 38 days 3 hours 15 minutes and counting) - is the world’s biggest (sport) event with 32 national teams from...
-
Announcing CSV,Conf - the conference for data makers everywhere which takes place on 15 July 2014 in Berlin. This one day conference will focus on practical, real-world stories, examples and techniques of how to scrape, wrangle, analyze, and visualize data. Whether your data is big...
-
In an ideal world… In an ideal world we would go in search of a piece of data by using our favorite search engine and we would land on a page with a big download button. It would give you a few options for formats....
-
We’re back with a bumper crop of updates in this new edition of the now-monthly Labs newsletter! Textus Viewer refactoring The TEXTUS Viewer is an HTML + JS application for viewing texts in the format of TEXTUS, Labs’s open source platform for collaborating around collections...
-
This post looks at the Securities and Exchange Commission (SEC) EDGAR database. EDGAR is a rich source of data containing regulatory filings from publicly-traded US corporations including their annual and quarterly reports: All companies, foreign and domestic, are required to file registration statements, periodic reports,...
-
The past few weeks have seen major improvements to the Labs website, another Open Data Maker Night in London, updates to the TimeMapper project, and more. Labs Hangout: today The next Labs online hangout is taking place today in just a few hours—now’s your chance...
-
From now on, the Labs newsletter will arrive through a special announce-only mailing list, [email protected], more details on which can be found below. Keep reading for other new developments including the fifth Labs Hangout, the launch of SayIt, and new developments in the vision of...
-
Last time we talked about OLAP in general – what it is and why it is useful. Today we are going to look at the data – how they are structured and why? What are cubes? What does it mean “multi-dimensional”? Data Cubes and Logical...
-
Welcome back from the holidays! A new year of Labs activities is well underway, with long-discussed improvements to the Labs projects page, many new PyBossa developments, a forthcoming community hangout, and more. Labs projects page Getting the Labs project page organized better has been high...
-
What is OLAP? “Online Analytical Processing – OLAP is an approach to answering multi-dimensional analytical queries swiftly” says Wikipedia. What does that mean? What are multi-dimensional analytical queries? Why this approach? We will learn all this in a short blog series. The term OLAP is...
-
Data Converters is a command line tool and Python library making routine data conversion tasks easier. It helps data wranglers with everyday tasks like moving between tabular data formats—for example, converting an Excel spreadsheet to a CSV or a CSV to a JSON object. The...
-
We’re back after taking a break last week with a bumper crop of updates. A few things have changed: Labs activities are now coordinated entirely through GitHub. Meanwhile, there’s been some updates around the Nomenklatura, Annotator, and Data Protocols projects and some new posts on...
-
Recently I spent a week in Tanzania working on education data with the ministry of education (blog post here). One of the problems we faced there were spreadsheets, we liked to merge, without having any unique IDs. I quickly realized we can do this through...
-
This post introduces one of the handiest features of Data Pipes: fast (pre) viewing of CSV files in your browser (and you can share the result by just copying a URL). The Raw CSV CSV files are frequently used for storing tabular data and are...
-
Another busy week at the Labs! We’ve had lots of discussion around the idea of “bad data”, a blog post about Mark’s aid tracker, new PyBossa developments, and a call for help with a couple of projects. Next week we can look forward to another...
-
See also: “A closer look at aid in the Philippines” Since Typhoon Yolanda/Haiyan struck the Philippines on 8th November there has been some discussion around the availability of information to help coordinate activities effectively in the disaster response phase. To see what data was already...
-
This week, Labs members gathered in an online hangout to discuss what they’ve been up to and what’s next for Labs. This special edition of the newsletter recaps that hangout for those who weren’t there (or who want a reminder). Data Pipes update Last week...
-
We’ve just started a mini-project called Bad Data. Bad Data provides real-world examples of how not to publish data. It showcases the poorly structured, the mis-formatted, and the just plain ugly. This isn’t about being critical but about educating—providing examples of how not to do...
-
Labs was bristling with discussion and creation this week, with major improvements to two projects, interesting conversations around a few others, and an awesome new blog post. Data Pipes: lots of improvements Data Pipes is a Labs project that provides a web API for a...
-
This weekend the Google Developer Group in Cairo arranged 2-days workshops followed by a hackathon. During this event, I organized a workshop about NLTK and the use of Python in Natural Language Processing (NLP). The session’s slides can be found here. The beauty of NLP...
-
There was lots of interesting activity around Labs this week, with two launched projects, a new initiative in the works, and an Open Data Maker Night in London. Webshot: online screenshot service webshot.okfnlabs.org, an online service for taking screenshots of websites, is now live, thanks...
-
Data Issues is a prototype initiative to track “issues” with data using a simple bug tracker—in this case, GitHub Issues. We’ve all come across “issues” with data, whether it’s “data” that turns out to be provided as a PDF, the many ways to badly format...
-
If you are an open data researcher you will need to handle a lot of different file formats from datasets. Sadly, most of the time, you don’t have the opportunity to choose which file format is the best for your project, but you have to...
-
TimeMapper lets you create elegant and embeddable timemaps quickly and easily from a simple spreadsheet. A timemap is an interactive timeline whose items connect to a geomap. Creating a timemap with TimeMapper is as easy as filling in a spreadsheet template and copying its URL....
-
Datapackages are a neat idea along the “using data like we use code” way. While Tryggvi has created a nice python module to handle datapackages - there is a problem using datapackages in javascript. In an ideal world I’d just call something like d3.csv() on...
-
Herewith is a report on recent improvements to PublicBodies.org, our project in Open Knowledge Foundation Labs project to provide “a URL (and information) on every “public body” - that’s every government funded agency, department or organization. New data New data contributed over the last couple...
-
Someone just pointed me at this post from Ben Balter about Data as Code in which he emphasizes the analogies between data and code (and especially open data and open-source – e.g. “data is where code was 2 decades ago” …). I was delighted to...
-
The city of Vienna started releasing waiting times for some of its service offices recently. I followed my usual hunch and just wrote a small script on scraperwiki that stows away the JSON released by the city not knowing yet what to do with it....
-
Recently, I was at Chicas Poderosas in Bogota - the three day event featured talks on two days and a hackday on the last. During the event I was approached by Natalia an industrial designer who introduced a project of hers: Electrocardiogr_ama. She wanted to...
-
Data Pipes provides an online service built in NodeJS to do simple data transformations – deleting rows and columns, find and replace, filtering, viewing as HTML – and, furthermore, to connect these transformations together Unix pipes style to make more complex transformations. Because Data Pipes...
-
I’m pleased to announce the Miga Data Viewer, or Miga, an open source tool I created that lets you create a web/mobile app nearly automatically from a set of CSV data. There are already various applications/frameworks that provide a JavaScript-enabled front-end for structured data -...
-
From theory to experimentation Back in November 2010, I faced a problem while teaching my students about the Semantic Web. I wanted to convey the idea that Semantic Web technologies can break down the barriers between dataset silos on the Web and simplify the publication...
-
Tonight a couple of us were having a discussion on the OpenSpending IRC channel on how we can promote and better document the usage of the API. Tony had already begun to work on OpenSpending using R. I had previously done so as well. This...
-
A few years ago at the Eastern Conference for Workplace Democracy in New Hampshire, a bunch of friends chatting on a grassy knoll realized they were all working on overlapping directories of their communities, and decided to pool their efforts. They tracked down some techies...
-
This last weekend, CERN hosted a very special event: the 2nd CERN Summer Student Webfest organized by the Citizen Cyberscience Centre. The Webfest invites CERN summer students to participate in a 48 hours marathon hacking new applications, tools, games, etc. about physics. This year, I...
-
data.okfn.org is the Labs’ repository of high-quality, easy-to-use open data. This update summarizes some of the improvements to data.okfn.org that have taken place over the past two months. New tools Several tools which make it easier to use the Data Package standard are now operational....
-
CrowdCrafting.org hosts a wide variety of applications that range from science to humanities. Since the official launch of CrowdCrafting.org, lots of applications have been created , but one of them has done a really impressive job: Héraðsdómar - sýknað eða sakfellt. Héraðsdómar - sýknað eða...
-
For a while I’ve been thinking about how to make Open Data more tangible. Even with great visualizations, it tends to remain stuck in computers and smartphones. Recently, I had the idea to start taking geodata, released by cities, and start making it into physical...
-
Having developed the Greek DBpedia, the first Internationalized DBpedia, OKFN Greece is now involved in the OKFN Labs by introducing three applications using DBpedia. 1. DBpedia Spotlight DBpedia Spotlight is an application that automatically spots and disambiguates words or phrases of text documents that might...
-
Spanish society has been bombarded recently with a flurry of news stories about possible cases of corruption in the major political parties like the Partido Socialista Obrero Español and the Partido Popular. In January of 2013 the party that rules the country, Partido Popular (PP),...
-
There have been many new developments with PublicBodies.org, the Labs project which aims to provide “a URL for every part of government”, since the last update on the Labs blog. The news includes: a new and improved backend; a push for integration with Nomenklatura; discussion...
-
The next Open Data Maker Night London will be on Tuesday 16th July 6-9pm (you can drop in any time during the evening). Like the last two it is kindly hosted by the wonderful Centre for Creative Collaboration, 16 Acton Street, London. When: Tuesday 16th...
-
Back in April, I wrote on the Open Knowledge Foundation main blog to launch the first component of our Aid Transparency Tracker, a tool to analyse aid donors’ commitments to publish more open data about their aid activities. At the end of that post, I...
-
ElasticSearch is a great open-source search tool that’s built on Lucene (like SOLR) but is natively JSON + RESTful. Its been used quite a bit at the Open Knowledge Foundation over the last few years. Plus, as its easy to setup locally its an attractive...
-
Data Explorer is a client-side web application for data processing and visualization. With Data Explorer, you can import data, transform it with JavaScript code, and visualize it on a graph or a map – all fully within the browser and with your data and code...
-
This is the first of regular updates on Labs project http://data.okfn.org/ and summarizes some of the changes and improvements over the last few weeks. 1. Refactor of site layout and focus. We’ve done a refactor of the site to have stronger focus on the data....
-
Our next Open Humanities Hangout will take place next Tuesday, 28th May. This is the latest in the series of regular hangouts we’ve been organizing over the past few months with people interested in tapping in to the growing amount of open cultural data and...
-
Nomenklatura is a simple service that makes it easy to maintain a canonical list of entities such as persons, companies or event streets and to match messy input, such as their names against that canonical list – for example, matching Acme Widgets, Acme Widgets Inc...
-
This is an update on PublicBodies.org - a Labs project whose aim is to provide a “URL for every part of Government”: http://publicbodies.org/ PublicBodies.org is a database and website of “Public Bodies” – that is Government-run or controlled organizations (which may or may not have...
-
I’m playing around with some large(ish) CSV files as part of a OpenSpending related data investigation to look at UK government spending last year – example question: which companies were the top 10 recipients of government money? (More details can be found in this issue...
-
I’ve been working to get Greater London Authority spending data cleaned up and into OpenSpending. Primary motivation comes from this question: Which companies got paid the most (and for doing what)? (see this issue for more) I wanted to share where I’m up to and...
-
sqlaload is a small library that I use to handle databases in Python data processing. In many projects, your process starts with very messy data (something you’ve scraped or loaded from a hand-prepared Excel sheet). In subsequent stages, you gradually add cleaned values in new...
-
At the Culture Labs hangout yesterday we wrote up the plans for the next steps for Textus we have been discussing over the last few months. The result is this slide deck overview. It both introduces Textus and outlines next steps (slide 12 onwards). Key...
-
This is an update on progress with the Data Explorer (aka Data Transformer). Progress is best seen from this demo which takes you on a tour of house prices and the difference between real and nominal values. More information on recent developments can be found...
-
Over time Recline JS has grown. In particular, since the first public announce of Recline last summer we’ve had several people producing new backends and views (e.g. backends for Couch, a view for d3, a map view based on Ordnance Survey’s tiles etc etc). As...
-
I’m really happy to announce that today we have finally added a feature that will allow to export your data into a CSV format with just one click (we also support the same for JSON). For this purpose, all the applications in PyBossa now feature...
-
 Last Saturday, the 26th of January, Mozilla held in parallel in 25 cities all over the world a hack day, the #FirefoxOSAppDay, about creating new web applications for their new FirefoxOS mobile OS and the desktop web browser (this stills in beta and alpha mode!)....
Last Saturday, the 26th of January, Mozilla held in parallel in 25 cities all over the world a hack day, the #FirefoxOSAppDay, about creating new web applications for their new FirefoxOS mobile OS and the desktop web browser (this stills in beta and alpha mode!).... -
In the last weeks we have been working hard in order to make easier to develop new PyBossa applications. For this reason, we are happy to announce a new version of PyBossa.JS. This new version introduces several improvements: Creating an app is much easier! You...
-
 At the Open Interests hackday in November, a discussion with Martin Stabe from the FT’s interactive desk led a prototype of Journoid. The idea is to monitor changing on-line datasets for remarkable information, like earthquakes, procurement in a particular industry or a close parliamentary vote....
At the Open Interests hackday in November, a discussion with Martin Stabe from the FT’s interactive desk led a prototype of Journoid. The idea is to monitor changing on-line datasets for remarkable information, like earthquakes, procurement in a particular industry or a close parliamentary vote.... -
I’ve traditionally used python for web scraping but I’d been increasingly thinking about using Node given that it is pure JS and therefore could be a more natural fit when getting info out of web pages. In particular, when my first steps when looking to...
-
There are many circumstances where you want to archive a tweets - maybe just from your own account or perhaps for a hashtag for an event or topic. Unfortunately Twitter search queries do not give data more than 7 days old and for a given...
-
 If you compare software code and legislation you can find many similarities: both are big bodies of text spread over multiple units (laws/files). The total amount of text inevitably grows bigger over time with many small changes to existing parts while most of the corpus...
If you compare software code and legislation you can find many similarities: both are big bodies of text spread over multiple units (laws/files). The total amount of text inevitably grows bigger over time with many small changes to existing parts while most of the corpus... -
Thanks to the free crowd-crafting tool PyBossa, nowadays the biggest challenge for successful crowd-sourcing is engaging users for participating in tasks, and to keep that motivation at a high level over time. Therefor the user experience of crowd-sourcing apps plays a crucial role. After participating...
-
This post is a rough and ready overview of various javascript timeline libraries that arose from research in creating a timeline view for Recline JS. Note this material hung around on my hard disk for a few months so some of it may already be...
-
 Making sense of massive datasets that document the processes of lobbying and public procurement at European Union level is not an easy task. Yet a group of 25 journalists, developers, graphic designers and activists worked together at the Open Interests Europe hackathon last weekend to...
Making sense of massive datasets that document the processes of lobbying and public procurement at European Union level is not an easy task. Yet a group of 25 journalists, developers, graphic designers and activists worked together at the Open Interests Europe hackathon last weekend to... -
How much does the highest paid person in the Brazilian Federal Senate earns? That’s the question I asked myself a few weeks ago, and one that should be easy to answer. In Brazil, every public body must publish its employees’ salaries online, but some do...
-
We’ve recently finished a demo for ReclineJS showing how it can be used to build JS-based (ajax-style) search interfaces in minutes (or even seconds!): http://reclinejs.com/demos/search/ Because of Recline’s pluggable backends you get out of the box support for data sources such as SOLR, Google Spreadsheet,...
-
We’re having the next Show and Tell on Friday, 26 October at 2:30 pm BST via Google Hangout on Air. As usual, the URL will be posted on OKFN Labs’ G+ Page. If you’d like to present, add your name to the list. Remember, #okfn...
-
 One of the largest data collection projects we have done so far has been the consolidation of the UK’s departmental expenditure. Over 370 different government entities have published a total of more than 7000 spreadsheets. Many of those have obviously been hand-crafted or at least...
One of the largest data collection projects we have done so far has been the consolidation of the UK’s departmental expenditure. Over 370 different government entities have published a total of more than 7000 spreadsheets. Many of those have obviously been hand-crafted or at least... -
 The European Journalism Centre and the Open Knowledge Foundation, sponsored by Knight-Mozilla OpenNews, invite you to the Open Interests Hackathon to track the the interests and money flows which shape European policy. When: 24-25 November Where: Google Campus Cafe, 4-5 Bonhill Street, EC2A 4BX London...
The European Journalism Centre and the Open Knowledge Foundation, sponsored by Knight-Mozilla OpenNews, invite you to the Open Interests Hackathon to track the the interests and money flows which shape European policy. When: 24-25 November Where: Google Campus Cafe, 4-5 Bonhill Street, EC2A 4BX London... -
Built an app or tool you want to show people? Played around with some interesting data? Know of a new development people should know about? Want to find out what others are doing? Come to the Show and Tell this Friday and share what you...
-
 Last week, Matej Kurian published a message on the okfn-labs mailing list, describing the various sources he had discovered for machine-readable excerpts of the EU’s joint procurement system, TED. What struck me about this message was that, apparently, this polite and brilliant policy wonk had...
Last week, Matej Kurian published a message on the okfn-labs mailing list, describing the various sources he had discovered for machine-readable excerpts of the EU’s joint procurement system, TED. What struck me about this message was that, apparently, this polite and brilliant policy wonk had... -
WikipediaJS is a simple JS library for accessing information in Wikipedia articles such as dates, places, abstracts etc. The library is the work of Labs member Rufus Pollock. In essence, it is a small wrapper around the data and APIs of the DBPedia project and...
-
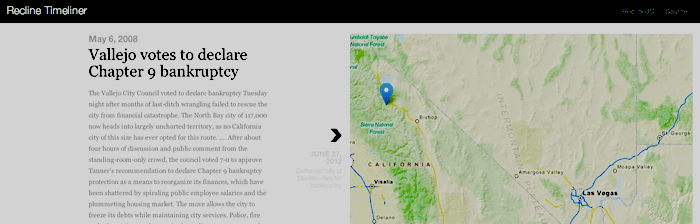 As part of the Recline launch I put together quickly some very simple demo apps one of which was called Timeliner: http://timeliner.reclinejs.com/ This uses the Recline timeline component (which itself is a relatively thin wrapper around the excellent Verite timeline) plus the Recline Google docs...
As part of the Recline launch I put together quickly some very simple demo apps one of which was called Timeliner: http://timeliner.reclinejs.com/ This uses the Recline timeline component (which itself is a relatively thin wrapper around the excellent Verite timeline) plus the Recline Google docs... -
This a brief post to announce an alpha prototype version of the Data Transformer, an app to let you clean up data in the browser using javascript: http://transformer.datahub.io/ 2m overview video: What does this app do? You load a CSV file from github (fixed...
-
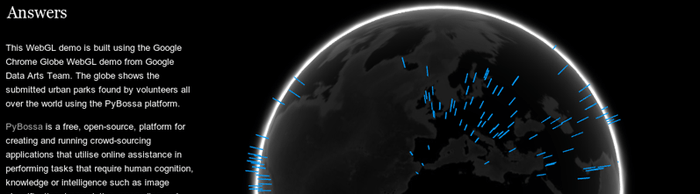 Labs member Daniel Lombraña González has built a 3-d globe showing the locatoins of urban parks around the world as located by volunteers using the Pybossa Urban Park geocoding app: http://teleyinex.github.com/pybossa-urbanpark-globe/ — (Source code) Background The Urban Parks geo-coding application is a micro-tasking app running...
Labs member Daniel Lombraña González has built a 3-d globe showing the locatoins of urban parks around the world as located by volunteers using the Pybossa Urban Park geocoding app: http://teleyinex.github.com/pybossa-urbanpark-globe/ — (Source code) Background The Urban Parks geo-coding application is a micro-tasking app running... -
On June 21st, the Knight News Challenge Round on Data ended. The day before, Rufus, Ross and I sat down to write out some ideas that we’d been discussing for a while. While we submitted proposals for Grano and DataProtocols, we decided to hold back...
-
On June 21st, the Knight News Challenge Round on Data ended. The day before, Rufus, Ross and I sat down to write out some ideas that we’d been discussing for a while. The first idea I want to repost here is a proposal for Grano,...
Have your say!
Do you have a topic that you'd like to write about? We love guest posts. Here's how to submit one »
Blogroll
Some places we find inspiration:
- Code for America
- World Bank Dataviz and Maps
- ProPublica Nerd Blog
- UK Government Digital Service
- Tactical Technology: In the Loop
- DevelopmentSeed
- vis4.net
- DataDrivenJournalism.net
- Open Institute - Kenya
- IRE: Behind the Story
- Sunlight Foundation Blog
- Organized Crime and Corruption Reporting Project
- ScraperWiki Blog