Bubbles: Python ETL Framework (prototype)
Introduction and ETL
The abbreviation ETL stands for extract, transform and load. What is it good for? For everything between data sources and fancy visualisations. In the data warehouse the data will spend most of the time going through some kind of ETL, before they reach their final state. ETL is mostly automated, reproducible and should be designed in a way that it is not difficult to track how the data move around the data processing pipes.
Data warehouse stands and falls on ETLs.
Bubbles
Bubbles is, or rather is meant to be, a framework for ETL written in Python, but not necessarily meant to be used from Python only. Bubbles is meant to be based rather on metadata describing the data processing pipeline (ETL) instead of script based description. The principles of the framework can be summarized as:
- ETL is described as a data processing pipeline which is an directed graph
- Processing operations are nodes in the graph, such as aggregation, filtering, dataset comparison (diff), conversion, …
- Nodes might have multiple different inputs and a single output (there might be multiple outgoing connections, but all of them are the same) – the inputs are considered operands to the operation and the output is the operation result.
- Data do not flow, if it is not necessary
The pipeline is described in a such way, that it is technology agnostic – the ETL developer, the person who wants data to be processed, does not have to care about how to access and work with data in particular data store, he can just focus on his task – deliver the data in the form that he needs to be delivered.
Data Objects and Data Store
The core of Bubbles are data objects – abstract concept of datasets which might have multiple internal representations. What actually flows between the nodes are not data itself, but those virtual representations of data and their compositions. Data are fetched only if it is really necessary – if there is no other option how to compose the data, such as join between a database table and a CSV file.
Here are few objects with different representations:
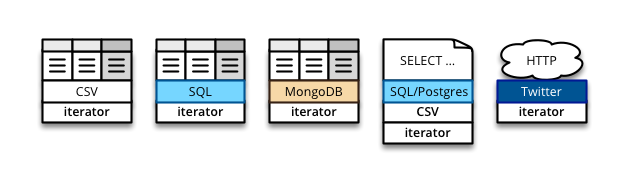
The objects are:
- object which originates from a CSV file, can be processed mainly using the python iterators, however retains its text CSV nature, just in case some of the nodes might know how to work with it more efficiently, for example row filtering without actually parsing the CSV into row objects
- SQL object representing a table – it can be composed into other SQL statements or can be used directly as a Python iterable
- MongoDB collection – similar to the previous SQL table, can be iterated as raw stream of documents
- SQL statement which might be a result of previous operations or our custom complex query. It can be used as such statement and composed with further operations, or the data can be fetched and iterated over in Python. Since this SQL object comes from a known database (PostgreSQL in this case) which implements a COPY command that generates CSV output, we can treat that object as such and provide the option to use CSV representation as well
- Twitter API object – an exampple of a data object that actually does not exists for us as a physical table, we do not even know from how many original tables the Twitter is feeding us the data and we do not have to care at all. We are just fine that we can have an impression of iterable dataset.
To be more concrete, take a simple filtering for example. Say we have sample of Tweets stored in a SQL database, MongoDB and obviously on Twitter. We want to get all tweets by OKFN. In SQL we use a SQL driver, connect to the database and do:
SELECT * FROM WHERE screen_name = 'okfn'
in Mongo we use a mongodb driver, connect to the database and do:
db.tweets.find(
{ },
{ screen_name: 'okfn'}
)
and in Twitter we just issue the following HTTP request:
https://api.twitter.com/1/statuses/user_timeline.json?screen_name=okfn
We asked for the same data object – a tweet in three different data stores. We had to use three different approaches. It does not look bad for us, “the tech people”. What if we can just write:
p = Pipeline(...)
p.source("data", "tweets")
p.filter_value("screen_name", "okfn")
p.pretty_print()
p.run()
The "data" is the data store. We as ETL designers do not have to worry what
kind of data store it is, how to talk to it, how to get data from it.
Now we would like to count the tweets, so let us add aggregate() operation,
which by default yields only record count:
p = Pipeline(...)
p.source("data", "tweets")
p.filter_value("screen_name", "okfn")
p.aggregate()
p.pretty_print()
p.run()
What happens here? For example, in the SQL case the COUNT() aggregation
function will be used. For twitter, because our backend does not know better,
the tweets will have to be pulled all from the Twitter API and counted
one-by-one. Which is sad, but good for our example. The objective was to
deliver the desired result, which happened.
Context
One thing is missing in my examples above: Pipeline(...) – the pipeline
works in a context. We need to provide the description of data stores. For
example:
stores = { "data": {"type": "sql", "url": "postgresl://localhost/twitter" }}
Stores have an interface for getting datasets by name or creating new datasets. Dataset might be:
- table in a SQL store
- collection in a MongoDB store
- CSV file in a store represented by a directory of CSV files
- JSON newlline delimited file in a store represented by a directory of JSOND files
- resource collection over an API, such as the Twitter example above
- dataset from a datapackage
ETL designer should not care about the underlying implementation, he should
care only about having “a set of data that look like a table”. Object dataset
responds to methods such as object_names() or get_object(name).
Operations
The ETL operations work on data objects provided as operands. An operation
returns another data object. As mentioned above, the flow of data is just
virtual. That means that when we are filtering the data, the framework might
be actually composing a SQL WHERE statement instead of just pulling the data
out of the database and filtering them row-by-rown in Python.
Similar with fields in the dataset – if we want to keep just certain columns,
why to pass them around all in the first place? Why not to ask only for those
that we actually need at the end? That is what Bubbles should do. Therefore
the keep_fields() operation just selects certain columns when used in the
SQL context.
There might be multiple implementations of the same operation. Which
implementation (function) is used is determined at the time of pipeline
execution. aggregate() might be in-python row-by-row aggregation using a
dictionary or it might be SUM() or AVG() with GROUP BY statement in SQL,
depending on which kind of object is passed to the operation.
In the following image you might see how the most appropriate operation is chosen for you depending on the data source. You can also see, that for certain representations the operations are combined together to produce just single data query for the source system:
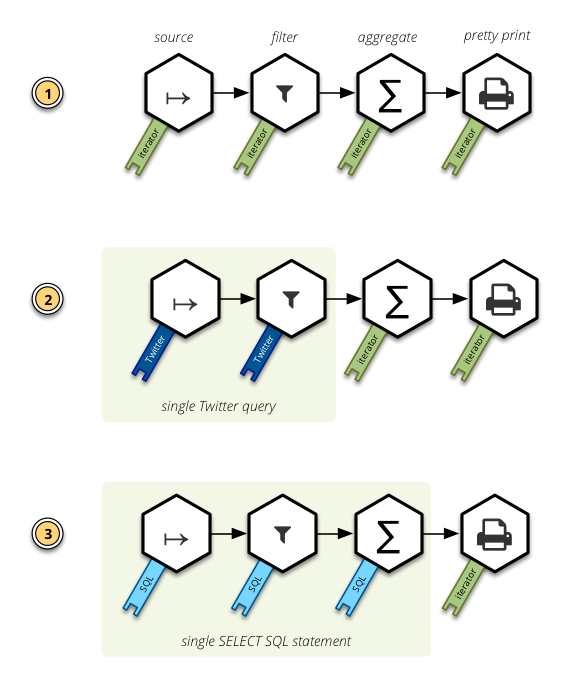
Examples
Here is an example of Bubbles
framework in action: “list customer details of customers who ordered something
between year 2011 and 2013”. You might see that the source is a directory of
CSV files. For comparison on the SQL example we create() a table, so the
rest of the pipeline will hapen as SQL, not in Python.
Another example showing aggregation joining of details.
An example that uses a data package (according to spec) as a data store:
The pipeline looks like this:
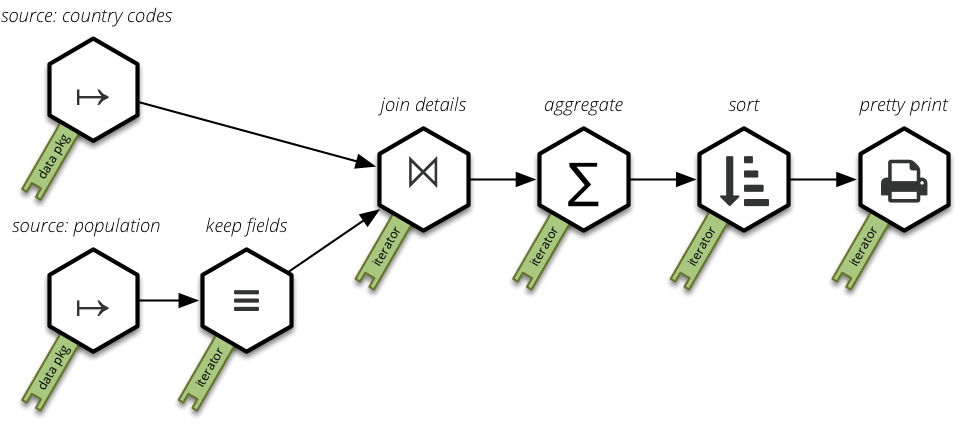
The Python source code for the pipeline:
# Aggregate population per independence type for every year
# Sources: Population and Country Codes datasets
#
from bubbles import Pipeline
# List of stores with datasets. In this example we are using the "datapackage"
# store
stores = {
"source": {"type": "datapackages", "url": "."}
}
p = Pipeline(stores=stores)
# Set the source dataset
p.source("source", "population")
# Prepare another dataset and keep just relevant fields
cc = p.fork(empty=True)
cc.source("source", "country-codes")
cc.keep_fields(["ISO3166-1-Alpha-3", "is_independent"])
# Join them – left inner join
p.join_details(pop, "Country Code", "ISO3166-1-Alpha-3")
# Aggregate Value by status and year
p.aggregate(["is_independent", "Year"],
[["Value", "sum"]],
include_count=True)
# Sort for nicer output...
p.sort(["is_independent", "Year"])
# Print pretty table.
p.pretty_print()
p.run()
Note about Metadata
I have been using Python as a scripting language to define my pipelines.
Observant reader might have noticed, that all I did was just composition of
some messages, which is true. The p Pipeline object contains just a graph
and the run() method uses an execution engine to resolve the graph and pick
the appropriate operations for the given thask. That means, my whole
processing pipeline does not need to be written in Python at all. It migh be
described as a JSON for example, it might even be generated from some
graphical user inteface for flow based programming.
There is more into metadata in Bubbles than mentioned in this blog post.
The framework understands higher level metadata, such as analytical – role of
a field from data analysis perspective. For example the aggregate()
operation might by default aggregate all fields that are of analytical type
measure and that information is passed on. Which results in less writing and
less noise on the side of pipeline designer.
Summary
Why should someone who just wants to achieve his goal of extracting, transforming and presenting the data care about the underlying technology and query language? Mostly these days when we are dealing with so many systems it is an unnecessary distraction. Moreover, many ETL blocks are generic and reusable, why we would have to write the same code for every system we use?
Having an abstract ETL framework allows us to share transformations, cleaning methods, quality checks and more much easier.
In addition, it leaves the optimization of the process to the operation writers, to the people with technical skills, who know when it is good to move data over the networks and through the disks, or if we can just compose an operation and issue a sigle statment that the source system understands.
Future
The bubbles is still just a prototype, for the brave ones. But I would love to see it as a Python ETL/data integration framework. The short term needs and objectives are:
- Simpler pipeline definition interface, more functional programming oriented
- Larger library of higher level reusable components, such as dimension
loaders (there is
more into
UPSERTthat many of us think, but that is another story) - Easier way to write operations.
- Larger variety of supported backends and services
If anyone is willing to help to prototype, I will gladly guide him/her. Let us build a python open source integration framework together. Extensible. Understandable. Focused on the use, way of thinking and pipeline design workflow.
Links:
 We make tools, apps and insights using
open stuff
We make tools, apps and insights using
open stuff


Comments