Labs Projects

CKAN
CKAN is a powerful data management system that makes data accessible – by providing tools to streamline publishing, sharing, finding and using data. CKAN is aimed at data publishers (national and regional governments, companies and organizations) wanting to make their data open and available.
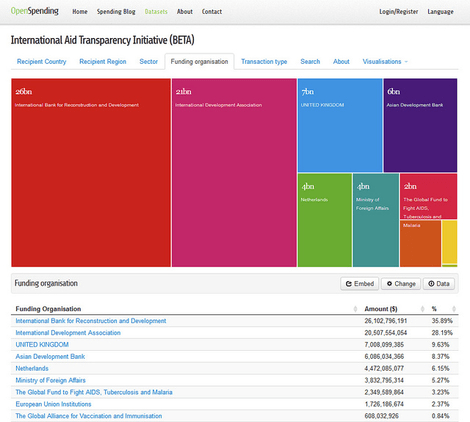
OpenSpending

OpenSpending exists to map the money worldwide – that is, to track and analyse public financial information globally. It is meant to be a resource for individuals and groups who wish to discuss and investigate public financial information, including journalists, academics, campaigners, and more.
OpenTrials

OpenTrials, a collaboration between Open Knowledge and Ben Goldacre (Senior Clinical Research Fellow in the Centre for Evidence Based Medicine at the University of Oxford), will aggregate information from a wide variety of existing sources, and aims to provide a comprehensive picture of the data and documents on all trials conducted on medicines and other treatments around the world.

DataHub.io
Datahub is a free, powerful data management platform from the Open Knowledge Foundation, based on the CKAN data management system.
OpenLiterature
Open Literature combines literary criticism and the internet to produce a platform for appreciating great literature.
Mira
This is a small application developed using Ruby-on-Rails. You upload a datapackage.json file to it along with the corresponding CSV files and it gives you a read-only HTTP API. It's pretty simple - it uses the metadata in the datapackage.json file to import each CSV file into its own database table. Once imported, various API endpoints become available for metadata and data. You can perform simple queries on the data, controlling the ordering, paging and variable selection. It also talks to the DataTables jQuery plug-in.
Puppycide Database Project

Puppycide Database Project is the largest public compilation of records related to killings of animals by police in the United States. The failure of US law enforcement to make records of lethal force available to the public has become a widely documented issue over the last few years. Despite the publicity, the issue remains unresolved at all levels of government - state, municipal and federal - leaving a small number of private, non-profit organizations to provide such basic information as human fatalities to researchers and journalists. The Puppycide Database Project is one such organization.
At present, the project relies on crowd-sourcing, and has developed several forms to record data and allow volunteers to encode existing database records for the purpose of Krippendorff’s alpha calculation. New records get announced via social media. We also provide a rapidly-growing library of legal documents & research related to police use of force issues - everything from lawsuit decisions to CDC emergency room admissions.
All of the core functionality for our project relies on open source applications. Some examples:
- Full text search capability using Sphinx
- Blog platform using ghost/nodejs
- Twitter connectivity using Codebird
Our biggest upcoming code project is the customization and implementation of a web crawler in order to accelerate the growth of our database. The crawler will seek and retrieve pages related to police use of force. In addition to adding more puppycide records, we will use the resulting information to study how news organizations report on issues of lethal force. This upcoming project could really use the input and advice of skilled developers and admins. Our biggest challenge is how to most effectively use the (very small) amount of resources available to us.
Good Tables
The Good Tables web service provides an API and UI for processing and validating tabular data, providing an http layer around the Good Tables Python library.
Currently, this means data can be provided in CSV or Excel format, and the file will be validated for well-formedness (for example, no empty rows or columns, no duplicate rows, all rows have valid dimensions, and so on), and conformance to a schema (if a JSON Table Schema is supplied).
Public Tika Server including OCR Service
This is a web service available for converting a multitude of document types to simple text. It is a public facing instance of the Apache Tika server (developer version). It lives at:
http://beta.offenedaten.de:9998/tika
To test it, just throw some images with text in them at it. For example, on a terminal on Mac or Linux:
curl -T tiff_example.tif http://beta.offenedaten.de:9998/tika
More details at http://okfnlabs.org/blog/2015/02/21/documents-to-text.html. Please note that Matt is not the author of the software, just the developer for the Dockerfile that makes setting up an instance of what is quite a large piece of software very straightforward.
2030 Watch
2030 Watch monitors progress towards the sustainable development goals (SDGs) from an independent, civil society-led perspective. Check it out at https://2030-watch.de/en/
DataPortals.org
DataPortals.org is the most comprehensive list of open data portals in the world. It is curated by a group of leading open data experts from around the world - including representatives from local, regional and national governments, international organisations such as the World Bank, and numerous NGOs.
Product Open Data

The goal of this project is to build the largest open product database in the world. Such a database would allow consumers to get information about a given product in real time by simply scanning its barcode with their mobile phone. It would also allow consumers to publish their opinions about products in an easily accessible way.
We are currently rebooting this project and are looking for contributors. An Android client (source) is available, and work has started on an iOS client. If you’d like to contribute or find out more, you can join the working group mailing list, follow the project on Twitter, and join the discussion on the Open Knowledge forum.
Webshot
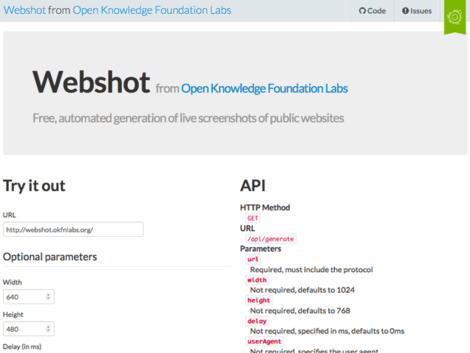
Webshot is a Node.js-based webservice provided by Open Knowledge Labs for taking automated screenshots of webpages using node-webshot. It is available for anyone to use. As always, contributions are welcome.
Public Bodies
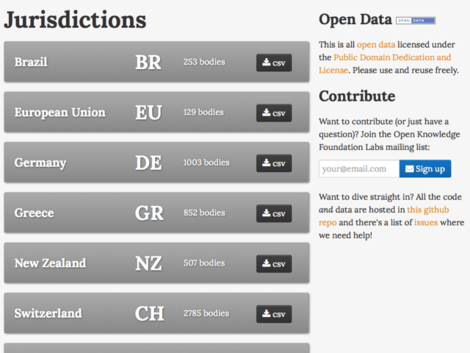
PublicBodies.org is a website hosting a database of so-called public bodies—that is government-run or -controlled organizations (which may or may not have a distinct corporate existence). Examples include government ministries or departments, as well as state-run organizations such as libraries, police and fire departments.
Contributions of additional data and better descriptions for new and existing jurisdictions are very welcome. Please add a CSV file via a pull request or take a look project’s issue queue.
FacetView
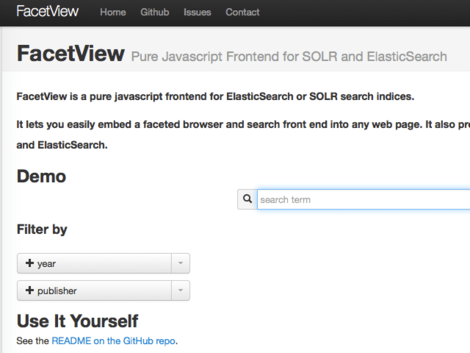
FacetView is a pure JavaScript frontend for ElasticSearch search indices. It lets you easily embed a faceted browser and search frontend into any web page. It also provides a micro-framework you can build on when creating user interfaces to ElasticSearch. It is currently used in the Open Knowledge Labs BibServer project.
BibServer
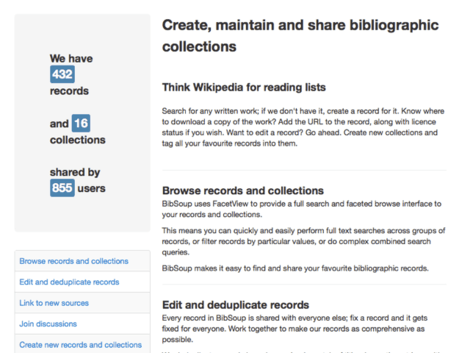
BibServer is an open-source RESTful bibliographic data server. BibServer makes it easy to create and manage collections of bibliographic records such as reading lists, publication lists and even complete library catalogs. FacetView is included to provide a rich interface for complex search queries. BibServer supports bibtex, MARC, RIS, BibJSON, RDF and other bibliographic formats.
BibJSON
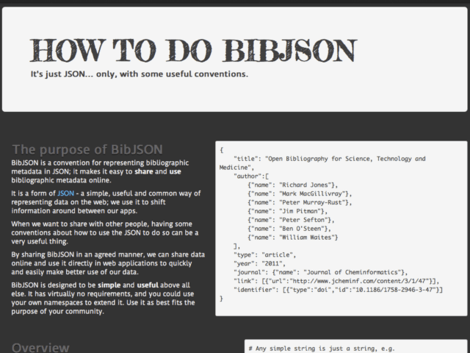
BibJSON is a convention for representing bibliographic metadata in JSON. It is intended as a specification for developers of web applications that generate or accept bibliographic metadata. It is currently used in the Open Knowledge Labs BibServer project.
Bad Data
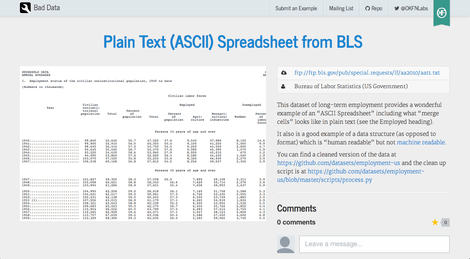
Bad Data is a site detailing real-world examples of how not to prepare or provide data. It showcases poorly structured, misformatted, or just plain ugly datasets and what they get wrong.
While its primary purpose is to serve as an educational tool for governments and other organizations, it is also a good source of practice material for budding data wranglers—those tasked with cleaning and transforming data. The project began as a place to keep practice data for Data Explorer, another project of Open Knowledge Labs.
Data Package Manager
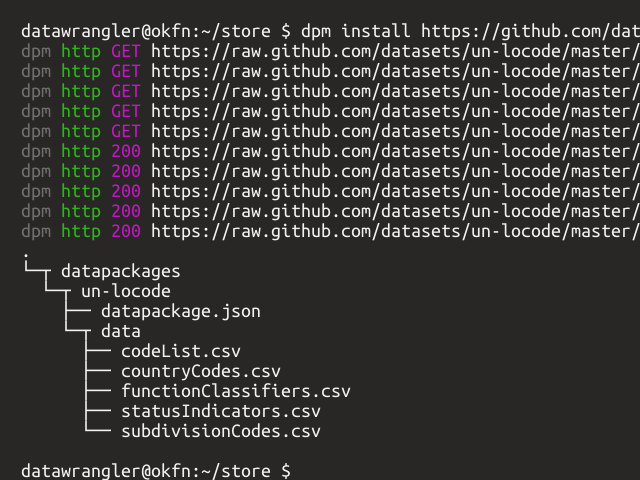
dpm (data package manager) is a library and
command-line tool for installing and
managing data
packages. Inspired by software package management tools
like apt for Debian, dpm aims
to reduce the friction of
sharing and working with data.
Recline Mozilla CSV Viewer
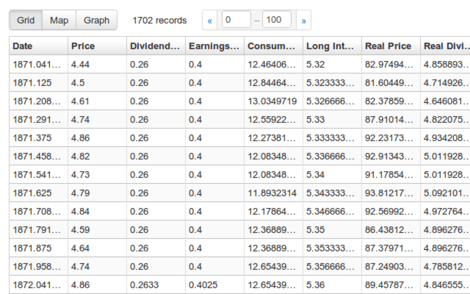
A FireFox extension which allows you to view, search, graph and map CSV files in the browser (built using Recline). This is an port of the great Rufus Pollock's chrome-csv-viewer on FireFox.
Open Knowledge Labs website

The Open Knowledge Labs website (i.e. the site you’re looking at right now) is itself a collaborative project of Open Knowledge. It is built using Jekyll, a static site generator, and hosted on GitHub Pages. You can contribute by addressing some of the items on the project’s GitHub issue queue (hint: you can start with the easy ones).
Head Start

Head Start is intended for scholars who want to get an overview of a research field. They could be young PhDs getting into a new field, or established scholars who venture into a neighboring field. The idea is that you can see the main areas and papers in a field at a glance without having to do weeks of searching and reading. A prototypical implementation for the field of educational technology can be found on Mendeley Labs. The visualization is also used in Conference Navigator 3 and in the Organic Edunet portal.
Ivo of Chartres
A collection of the works of Ivo, bishop of Chartres.
This site has four elements
- draft texts and some concordances for the three collections traditionally
associated with Ivo of Chartres:
- the Collectio Tripartita
- the Decretum and
- the Panormia
- a draft list of manuscripts which contain a significant number of Ivo’s letters.
CSV.js
Simple javascript CSV library focused on the browser with zero dependencies. Supports both parsing and serializing CSV.
Originally developed as part of ReclineJS but now fully standalone.
Data Pipes
Data Pipes is a service to provide streaming, "pipe-like" data transformations on the web – things like deleting rows or columns, find and replace, head, grep etc.
reconcile-csv
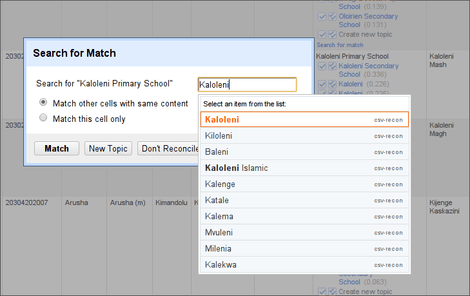
Reconcile-CSV is an OpenRefine reconciliation service running on top of a CSV file. It uses fuzzy matching to find the most likely candidates for matching. If you ever needed to join two datasets that didn't have unique identifiers and where things are written slightly different: this is a way to go.
Open Correspondence
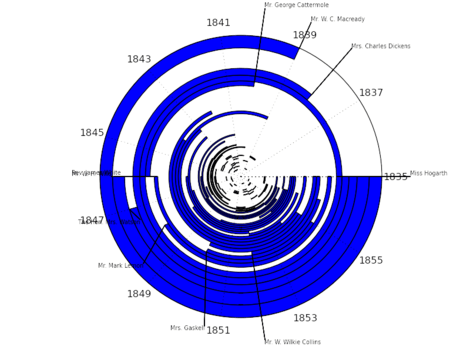
Open Correspondence is an attempt to explore the letters network of the nineteenth century. At the moment, the project contains some of the letters of Charles Dickens, but we're working to expand to it include many other authors such as Jane Austen, George Eliot and Byron.
ElasticSearch.JS
A simple javascript library for working with ElasticSearch.
It also provides a backend interface to ElasticSearch suitable for use with the Recline suite of data libraries.
Data Explorer
Data Explorer is an in-browser data cleaning and visualization app. Load tabular data, process it with JavaScript, and graph the results, all in the comfort of your browser. Gist-based persistence enables simple versioning and sharing of projects.
Frictionless Data
There’s too much friction working with data - friction getting data, friction processing data, friction sharing data.
This friction stops people doing stuff: stops them creating, sharing, collaborating, and using data - especially amongst more distributed communities. It kills the cycles of find, improve, share that would make for a dynamic, productive and attractive (open) data ecosystem.
We need to make an ecosystem that, like open-source for software, is useful and attractive to those without any principled interest, the vast majority who simply want the best tool for the job, the easiest route to their goal.
We think that by getting a few key pieces in place we can reduce friction enough to revolutionize how the (open) data ecosystem operates with massively improved data quality, utilization and sharing.
We’re creating:
- Standards: A small set of lightweight ‘data package’ standards and patterns providing a base structure on which tooling and integration can build.
- Tooling and Integration: Making it easy to use and publish data packages from your existing apps and workflows whether that’s Excel, R, or Hadoop!
- Outreach and Community: Engaging and evangelizing around the concepts, standards and tooling and building a community of users and contributors.
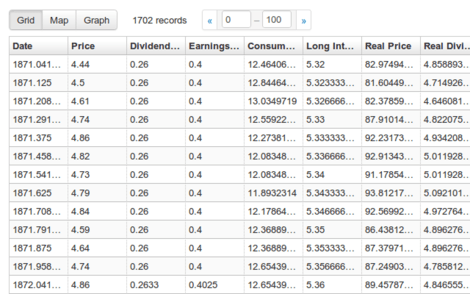
ReclineJS
Recline is a simple but powerful library for building data applications in pure Javascript and HTML. Building on Backbone, Recline supplies components and structure to data-heavy applications by providing a set of models (Dataset, Record/Row, Field) and views (Grid, Map, Graph etc).
Bubble Tree Library
The BubbleTree can be used to display hierarchical (spending) data in an interactive visualization. The setup is easy and independent from the OpenSpending platform. However, there is an optional integration module to connect with data from the OpenSpending API.
Nomenklatura
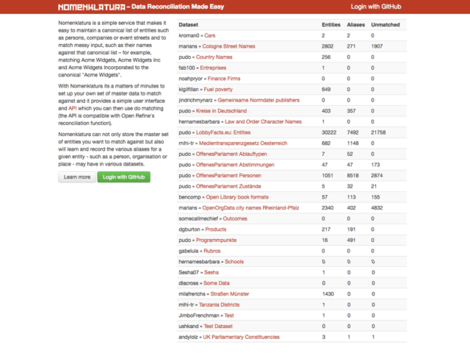
Nomenklatura de-duplicates and integrates different names for entities - people, organisations or public bodies - to help you clean up messy data and to find links between different datasets. The service will create references for all entities mentioned in a source dataset. It then helps you to define which of these entities are duplicates and what the canonical name for a given entity should be. This information is available in data cleaning tools like OpenRefine or in custom data processing scripts, so that you can automatically apply existing mappings in the future. The focus of nomenklatura is on data integration, it does not provide further functionality with regards to the people and organisations that it helps to keep track of.
Nomenklatura is a simple service that makes it easy to maintain a canonical list of entities such as persons, companies or event streets and to match messy input, such as their names against that canonical list – for example, matching Acme Widgets, Acme Widgets Inc and Acme Widgets Incorporated to the canonical "Acme Widgets".
With Nomenklatura its a matters of minutes to set up your own set of master data to match against and it provides a simple user interface and API which you can then use do matching (the API is compatible with Open Refine's reconciliation function).
Nomenklatura can not only store the master set of entities you want to match against but also will learn and record the various aliases for a given entity - such as a person, organisation or place - may have in various datasets.
CrowdCrafting & PyBossa
CrowdCrafting is a free, open-source crowd-sourcing and micro-tasking platform powered by the PyBossa software. This platform enables people to create and run projects that utilize on-line assistance in performing tasks that require human cognition such as image classification, transcription, geocoding and more. CrowdCrafting is there to help researchers, civic hackers and developers to create projects where anyone around the world with some time, interest and an Internet connection can contribute.
Froide

Froide is a Freedom of Information portal written in Python using the Django Web framework. It manages contactable entities, requests and much more. Users can send emails to these entities and receive public answers via the platform.
It was developed to power Frag den Staat – the German Freedom of Information Portal, but is internationalized, localized and themable and has deployed in several different countries.
Read more
Frag Den Staat

Germany Freedom of Information portal powered by the Froide platform. Responsible for managing over a 1/3 of all Freedom of Information request in Germany.
Annotator
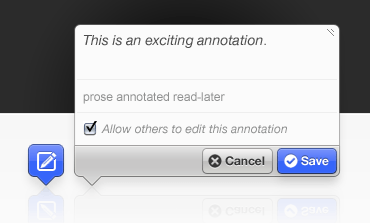
The Annotator is an open-source JavaScript library and tool that can be added to any webpage to make it annotatable. Annotations can have comments, tags, users and more. Morever, the Annotator is designed for easy extensibility so its a cinch to add a new feature or behaviour.
Retrato da Violência
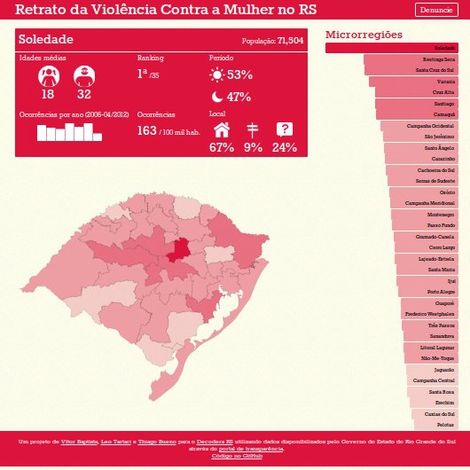
Visualization on violence against women in the brazilian state Rio Grande do Sul.
Textus

In a nutshell it is an open source platform for working with collections of texts. It enables students, researchers and teachers to share and collaborate around texts using a simple and intuitive interface.
IATI Tools
Library for working with IATI data and converting it into a relational database. http://blog.okfn.org/2012/06/05/from-xml-to-visualisations-iati/

Recline Chrome CSV Viewer
A chrome extension which allows you to view, search, graph and map CSV files in the browser (built using Recline)
Kartograph
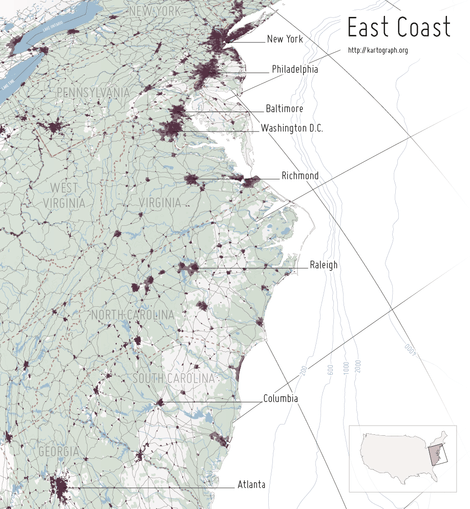
Kartograph is a simple and lightweight framework for building interactive map applications without Google Maps or any other mapping service. It was created with the needs of designers and data journalists in mind.
MessyTables

Tools for parsing messy tabular data. http://okfnlabs.org/blog/2012/10/22/messytables.html
Data Converters
Python library and command line tool for converting data from one format to another. It builds on messytables, GDAL and many more great open-source libraries for processing data, and provides one easy to use standard API.
WikipediaJS
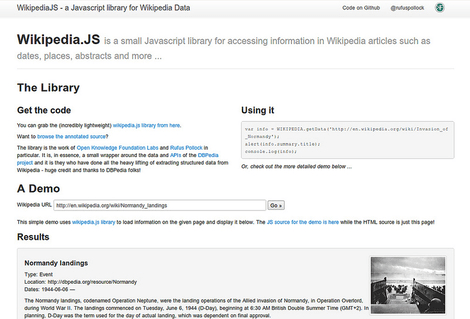
WikipediaJS is a simple JS library for accessing information in Wikipedia articles such as dates, places, abstracts etc. The library is the work of Labs member Rufus Pollock. In essence, it is a small wrapper around the data and APIs of the DBPedia project and it is they who have done all the heavy lifting of extracting structured data from Wikipedia - huge credit and thanks to DBPedia folks!
OffenesParlement

OffenesParlement is a site (and open-source codebase) for gathering and presenting information about the work of the Bundestag and Bundesrat.
MicroFacts
A web application to allow people to string together ‘factlets’ into narratives organized by theme, time and space.
Knowledgeforge
Create software tools to manage the collaborative development of open knowledge by different communities and individuals.
IsItOpenData
We aim to make it easy for people – like you – to make enquires of data holders, about the openness of the data they hold — and to record publicly the results of those efforts. We’re especially focused on scientific data but anyone can use this service.
OpenShakespeare
Open Source Shakespeare attempts to be the best free Web site containing Shakespeare’s complete works.
OpenEconomics
The Open Economics Working Group is run by the Open Knowledge Foundation in association with the Centre for Intellectual and Property Law (CIPIL) at the University of Cambridge. Its membership consists of leading academics and researchers, public and private sector economists, representatives from national and international public bodies and other experts from around the world. We want economics to be built on sound, transparent foundations, wherever possible. In particular, it is important that the data and associated analysis (particularly as represented in runnable code) be openly available to all members of society — not just other economists.
This working group therefore exists to:
- Act as a central point of reference and support for those interested in open economic data: that is, economic data which can be freely used, reused, and redistributed for any purpose (www.opendefinition.org).
- Identify best practice as well as legal, regulatory and technical standards for open economic data.
- Act as a hub for the development and maintenance of low-cost, community driven projects related to open material in economics.