Frictionless Data
Standards and tools to make a world of frictionless data
by Labs
There’s too much friction working with data - friction getting data, friction processing data, friction sharing data.
This friction stops people doing stuff: stops them creating, sharing, collaborating, and using data - especially amongst more distributed communities. It kills the cycles of find, improve, share that would make for a dynamic, productive and attractive (open) data ecosystem.
We need to make an ecosystem that, like open-source for software, is useful and attractive to those without any principled interest, the vast majority who simply want the best tool for the job, the easiest route to their goal.
We think that by getting a few key pieces in place we can reduce friction enough to revolutionize how the (open) data ecosystem operates with massively improved data quality, utilization and sharing.
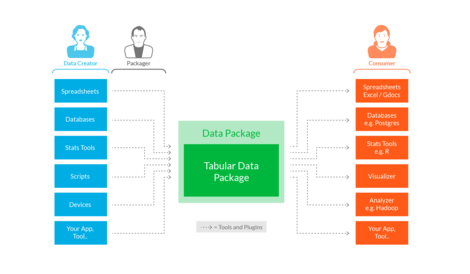
We’re creating:
- Standards: A small set of lightweight ‘data package’ standards and patterns providing a base structure on which tooling and integration can build.
- Tooling and Integration: Making it easy to use and publish data packages from your existing apps and workflows whether that’s Excel, R, or Hadoop!
- Outreach and Community: Engaging and evangelizing around the concepts, standards and tooling and building a community of users and contributors.
Related Posts
- Bootstrapping data standards with Frictionless Data
- Validating scraped data using goodtables
- Core Data on DataHub.io
- Data Package v1 Specifications. What has Changed and how to Upgrade
- Frictionless Data Specs v1 Updates
- DAC and CRS code lists – Now available as Frictionless Data!
- Introducing the new goodtables library and goodtables.io
- Case Studies for Frictionless Data
- Frictionless Data Specs Working Group
- Using Data Packages with Pandas
- Publish Data Packages to DataHub (CKAN)
- Using Data Packages with R
- Automated Data Validation with Data Packages
- Frictionless Data Transport in Python
- Introducing datapak - Work with Tabular Data Packages using Ruby and ActiveRecord
- Wanted - Data Curators to Maintain Key Datasets in High-Quality, Easy-to-Use and Open Form
- A Data API for Data Packages in Seconds Using CKAN and its DataStore
- Data Central: a static frontend for data package collections
- Labs newsletter: 30 January, 2014
- Labs newsletter: 21 November, 2013
- Data as Code Deja-Vu