
Frictionless Data Transport in Python
Tool and platform integrations for “Data Packages” are key elements of our Frictionless Data Initiative at Open Knowledge International. We recently posted on the main blog about some integration work funded by our friends at Google. We’ve built useful Python libraries for working with Tabular Data Packages in some of the most popular tools in use today by data wranglers and developers. These integrations allow for easily getting data into and out of your tool of choice for further manipulation while reducing the tedious wrangling sometimes needed. In this post, I will give some more details of the work done on adding support for these open standards within CKAN, Google’s BigQuery, and common SQL database software. But first, here is an introduction to the format for those who are unfamiliar.
Tabular Data Package
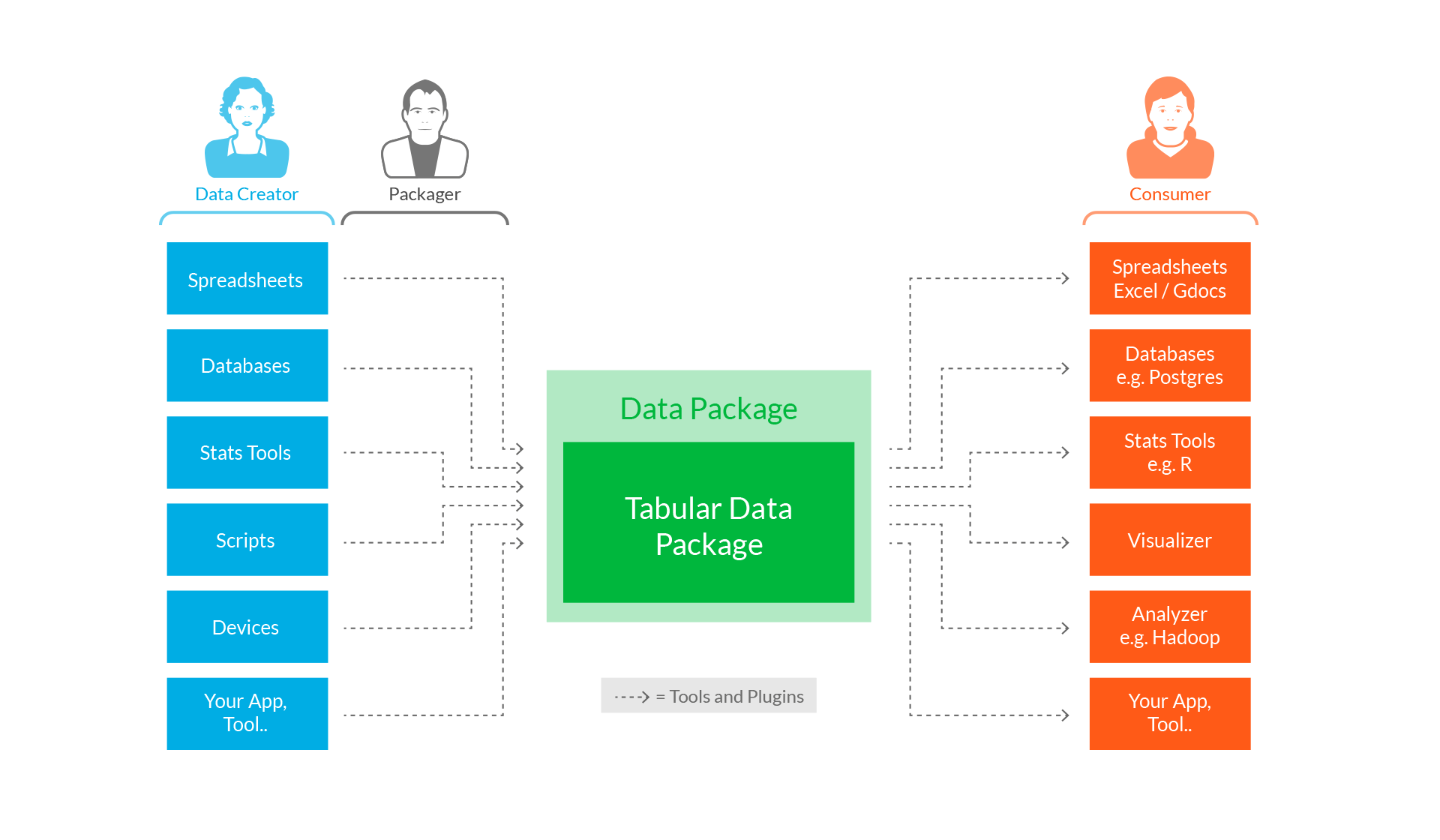
Tabular Data Package is a simple structure for publishing and sharing tabular data in CSV format. You can find more information about the standards here, but here are the key features:
-
Your dataset is stored as a collection of flat files.
-
Useful information about this dataset is stored in a specially formatted JSON file,
datapackage.jsonstored with your data. For tabular data, this information is a combination of general metadata and schema information.-
General metadata (e.g. name, title, sources) are stored as top-level attributes of the file
-
The exact schema (e.g. type, constraint information per column, and relations between resources) for the tabular data is stored in a resources attribute. For each resource, a schema is specified using the JSON Table Schema standard.
-
As an example, for the following data.csv file…
| date | price |
|---|---|
| 2014-01-01 | 1243.068 |
| 2014-02-01 | 1298.713 |
| 2014-03-01 | 1336.560 |
| 2014-04-01 | 1299.175 |
…we can define the associated datapackage.json file describing it:
{
"name": "gold-prices",
"title": "Gold Prices (Monthly in USD)",
"resources": [
{
"path": "data.csv",
"format": "csv",
"schema": {
"fields": [
{
"name":"date",
"type":"date"
},
{
"name":"price",
"type":"number",
"constraints": {
"minimum": 0.0
}
}
]
}
}
]
}
By providing a simple, easy-to-use standard for packaging data and building a suite of integrations to easily and losslessly import and export packaged data using existing software, we foresee a radical improvement in the quality and speed of data-driven analysis.
So, without further ado, let’s look at some of the actual tooling built :).
CKAN, originally developed by Open Knowledge, is the leading open-source data management system used by governments and civic organizations around the world. It allows organizations and ordinary users to streamline the publishing, sharing, and use of open data. In the US and the UK, data.gov and data.gov.uk run on CKAN, and there are many more instances around the world.
Given its ubiquity, CKAN was a natural target for supporting Data Packages, so we built a CKAN extension for importing and exporting Data Packages both via the UI and the API: ckanext-datapackager. This work replaces a previous implementation for an earlier version of CKAN.
CKAN Data Packager Extension
- Source and usage information: https://github.com/ckan/ckanext-datapackager
- Screencast (UI): https://youtu.be/qEaAJB_GYmQ
- Screencast (API): https://asciinema.org/a/8jrpft2etpubte8jupfko8ci5
BigQuery and SQL Integration
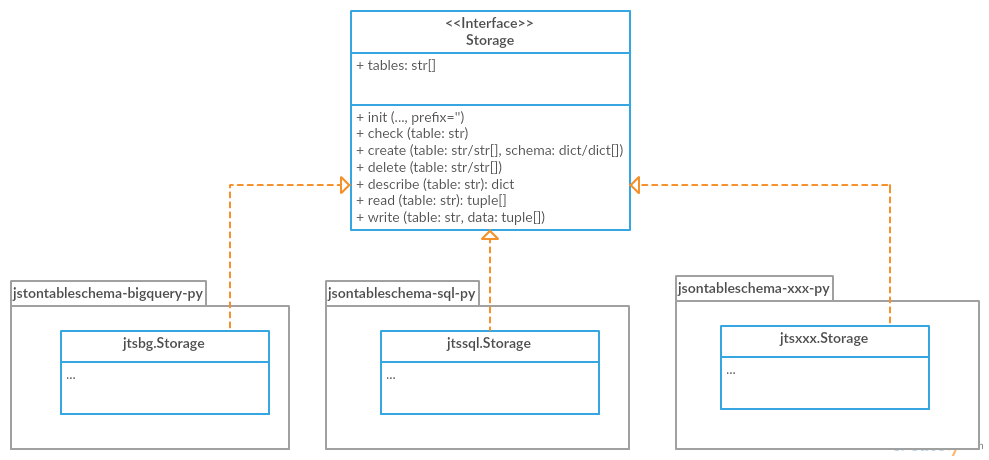
BigQuery is Google’s web service for querying massive datasets. By providing a Python library, we can allow data wranglers to easily import and export “big” Data Packages for analysis in the cloud. Likewise, by supporting general SQL import and export for Data Packages, a wide variety of software that depend on typical SQL databases can support Data Packages natively. The library powering both implementations is jsontableschema-py, which provides a high level interface for importing and exporting tabular data to and from Tabular Storage objects based on JSON Table Schema descriptors.
BigQuery
- Source: jsontableschema-bigquery-py.
- Screencast: https://www.youtube.com/watch?v=i_YHSwl-7VU
- Walkthrough: https://gist.github.com/vitorbaptista/998aed29097945aaccff
SQL
- Source and usage information: jsontableschema-sql-py.
- Screencast: https://asciinema.org/a/cyzd0lz0kqvcqmg4zneifohov
- Walkthrough: https://gist.github.com/vitorbaptista/19d476d99595584e9ad5
Beyond
This modular approach allows us to easily build support across many more tools and databases. We already have plans to support MongoDB and DAT. Of course, we need feedback from you to pick the next libraries to focus on. What tool do you think could benefit from Data Package integration? Tell us in the forum.
For more information on Data Packages and our Frictionless Data approach, please visit http://frictionlessdata.io/.
 We make tools, apps and insights using
open stuff
Join in »
We make tools, apps and insights using
open stuff
Join in »
 Follow @okfnlabs
Follow @okfnlabs

Comments