
Using Data Packages with Pandas
Frictionless Data is about making it effortless to transport high quality data among different tools and platforms for further analysis. We obviously ♥ data science, and pandas is one of the most popular Python libraries for advanced data analysis and modeling. This post highlights our most recent community contribution1—pandas integration for Data Packages—what it means, and how you can contribute.
Pandas
![]()
From the pandas documentation:
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python.
One of the primary data structures in pandas is the DataFrame. The DataFrame, similar to R’s data frame, stores the kind of 2-dimensional, tabular data common across various data analysis use cases. While pandas has extremely powerful tools for importing, exporting, and manipulating data, the process of loading data from, say, a single CSV file, often requires some trial and error to do optimally. For instance, one might need to manually specify CSV dialect parameters, index columns, datetime fields, etc. Pandas has automatic type and encoding guessing, but guessing often fails, requiring manual intervention to accurately describe and load your data. (See my recent post on R for an example of this.)
A Tabular Data Package consists of one or more CSV resources, each containing a schema (indicating type, constraints, and other metadata useful for validation and analysis) and, optionally, a dialect (specifying characters for separating or quoting values). See our JSON Table Schema guide and the CSVDDF specification for more information. Given that a single Tabular Data Package can consist of multiple tables, pandas integration means loading multiple DataFrames—with appropriately set types, encodings, indexes and dialects—at once. And once you have Tabular Data Packages in a pandas DataFrame, you now get all the power provided by Pandas to reshape, explore and visualise data as well as access to Pandas’ variety of export formats.
jsontableschema-pandas
The newly developed
Pandas plugin
allows users to generate and load Pandas DataFrames based on JSON
Table Schema descriptors. In order to use it, you first need to
install the datapackage and jsontableschema-pandas libraries.
pip install datapackage
pip install jsontableschema-pandasYou can load a Data Package into your environment by using the
datapackage.push_datapackage function. We pass a path to the
descriptor file (datapackage.json), and we are choosing pandas for
our backend:
import datapackage
import pandas
url = 'https://raw.githubusercontent.com/frictionlessdata/example-data-packages/master/cpi/datapackage.json'
storage = datapackage.push_datapackage(descriptor=url,backend='pandas')Once loaded into memory, the tables method returns a list of
DataFrames stored in the Data Package.
storage.tables['data__cpi']
In this case, we have a single table, data__cpi which we can take a
peek at using the Pandas head() method.
storage['data__cpi'].head()| Country Name | Country Code | Year | CPI | |
|---|---|---|---|---|
| 0 | Afghanistan | AFG | 2004-01-01 | 63.131893 |
| 1 | Afghanistan | AFG | 2005-01-01 | 71.140974 |
| 2 | Afghanistan | AFG | 2006-01-01 | 76.302178 |
| 3 | Afghanistan | AFG | 2007-01-01 | 82.774807 |
| 4 | Afghanistan | AFG | 2008-01-01 | 108.066600 |
At this point, you can treat storage['data__cpi'] as you would any
other DataFrame in Pandas. For more detail on how to interact with
the library and where to go from here, please visit below:
- Package on PyPI: https://pypi.python.org/pypi/jsontableschema-pandas
- Source on GitHub: https://github.com/frictionlessdata/jsontableschema-pandas-py
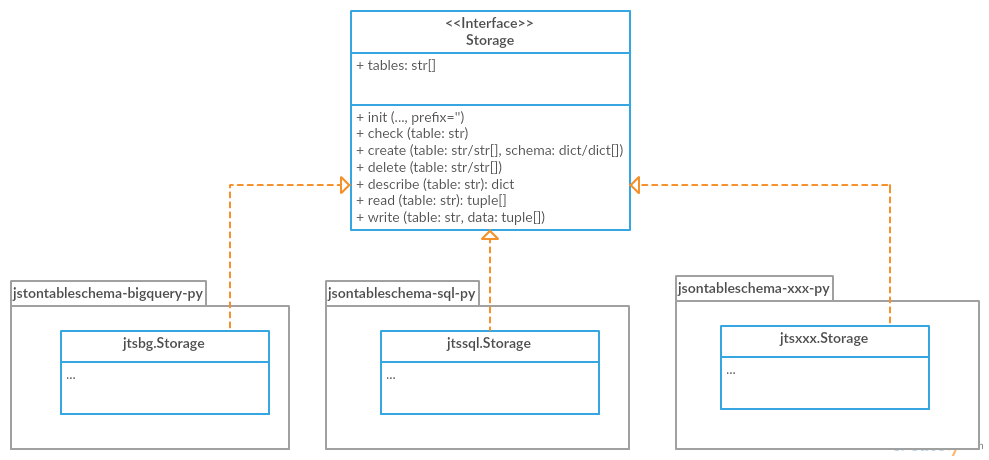
Contributing
The Python library
jsontableschema-py
provides the core set of utilities for working with Tabular Data
Package tables, and it implements a plugin-based system for adding
different
storage
backends. In a
recent post,
I highlighted the first two of these storage integrations:
SQL and
BigQuery.
These libraries, and the Pandas library, were written as drivers
implementing the jsontableschema.storage.Storage
interface.
If you have another storage backend you’d like to use with Data
Packages in Python, consider writing a
plugin.
We’re also looking to support other integrations beyond Python. You can find user stories we’re looking to support on the User Stories section of the Frictionless Data site. Do you have a library, tool, or platform that you’d like to see support importing and exporting Data Packages? Let us know by voting and commenting on what you’d like to see! If you have any questions about how to contribute, jump into the Frictionless Data chat or post in the forum.
To see the code used in this post, visit its Jupyter Notebook.
-
Thanks @sirex for the contribution! http://sirex.lt ↩
 We make tools, apps and insights using
open stuff
Join in »
We make tools, apps and insights using
open stuff
Join in »
 Follow @okfnlabs
Follow @okfnlabs

Comments