
Labs newsletter: Q4 2015
Hey there hackers & hackettes! Welcome to the 4th quarter 2015 Open Knowledge Labs Newsletter: A Very Special Holiday Edition of the Open Knowledge Labs Newsletter. We hope that all of our readers, volunteers, team members & contributors have a great holiday season. Labs is doing our part to keep things festive:

Despite the hustle and bustle of the season, we are happy to report that Labs has made some serious progress with our existing projects and that we also have a few very cool tools to assist with your year-end data analysis.
Tuttle - language, platform & version-control agnostic tool for collaborating on complex coding projects
Our very own @lexman (Alexandre Bonnasseau of mappy.com) was kind enough to provide Labs with a tool called tuttle that should come in handy when submitting code for large projects.
@lexman does an excellent job describing the purpose of tuttle in a recent post to the Labs discussion site:
“When we write scripts to create data, we don’t make it right on the first time. How many times did you have to comment the beginning of a script, so that executions jumps directly to a bug fix? With tuttle, you won’t have to. First, it computes only what is necessary : for example if a file has already been downloaded, it won’t do it again. But also, when you change a line of code, tuttle knows exactly what data must be removed and what part of the code must be run instead.”
Tuttle can be used to generate reports that generate workflows based on submission history and also highlight errors, as illustrated below (or in more detail here):
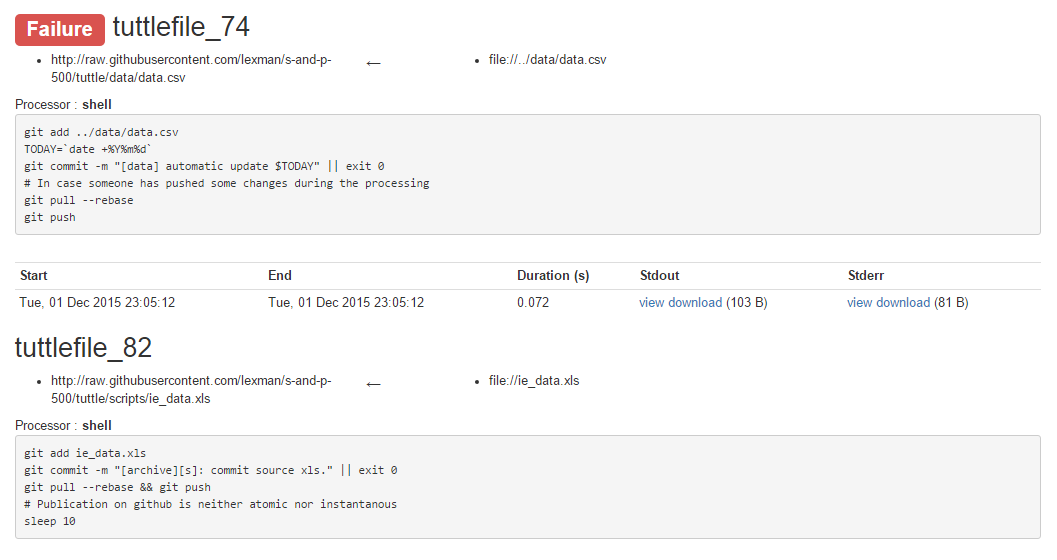
@lexman provides a detailed (and incredibly helpful) tutorial that helps acquaint new users with tuttle. We highly recommend giving the tutorial a try and using tuttle for complex development projects.
Mira turns CSV files into an HTTP API
Mira is a new tool that comes to Labs from @davbre and is built using Ruby on Rails & relies on Postgres. Mira allows users to generate an API using data packages, a way to describe csv files using JSON - greatly simplifying what can often be a lengthy, tedious process. Here is how @davbre describes his utility:
“This is a small application developed using Ruby-on-Rails. You upload a datapackage.json file to it along with the corresponding CSV files and it gives you a read-only HTTP API. It’s pretty simple - it uses the metadata in the datapackage.json file to import each CSV file into its own database table. Once imported, various API endpoints become available for metadata and data. You can perform simple queries on the data, controlling the ordering, paging and variable selection. It also talks to the DataTables jQuery plug-in.”
Python data analysis library Agate has reached version 1.1
A new Python library has begun to come of age. Agate was built by @onyxfish (NPR data journalist Christopher Groskopf) as an alternative to numpy and pandas. Whereas numpy and pandas were designed for scientists, Agate is designed with the needs of journalists in mind. Agate places a premium on ease of use and flexibility, even at the expense of performance optimazations present in other libraries. As @onyxfish puts it in a post announcing the new version of Agate:
“In greater depth, agate is a Python data analysis library in the vein of numpy or pandas, but with one crucial difference. Whereas those libraries optimize for the needs of scientists—namely, being incredibly fast when working with vast numerical datasets—agate instead optimizes for the performance of the human who is using it. That means stripping out those technical optimizations and instead focusing on designing code that is easy to learn, readable, and flexible enough to handle any weird data you throw at it.”
Agate’s leap from version 0.11.0 to version 1.0.0 on October 22nd of this year marked the first major release for the up-and-coming library (version 1.1 was released November 4th). While Agate was fully functional at v0.11.0, the changes since then have been substantial. Among some of the more impressive additions:
- Agate can now be used as a drop-in replacement for Python’s csv module
- Migrated csvkit‘s unicode CSV reading/writing support into agate
- 100% test coverage reached
- Added support for Python 3.5
- Massive performance increases for joins.
- Dozens of other resolved issues …
Agate has an impressive array of documentation for developers. Take a look at the manual, the standard tutorials, a tutorial for using Agate with Jupyter notebook, the Agate Cookbook and the Agate API documentation.
Agate does indeed look promising, and there is an immense need for tools like it. Journalism is changing rapidly. With a flood of new information from Open Data advocates (like Open Knowledge) making their way to the newsroom, organizations that can effectively interpret that data will maintain a significant advantage over their competitors. Meanwhile, the public can only benefit from more accurate analysis of larger sets of information that impact their lives. Clearly, the need for analytics that were once only required at university now extends beyond the Ivory Tower.
Webshot improvements
Webshot is a free, automated utility that allows for the generation of live screenshots. Screenshots serve an important role in demonstrating accountability (when content is removed, defaced or censored from the internet), but just as frequently are critical for troubleshooting & diagnostic services. There are many scenarios in which manually creating screenshots would not be feasible - because of routing issues, or because a screenshot needs to be generated at an exact time (Webshot can be called via an API).
The Github page for Webshot includes not just the Webshot source code, but also a node-based web server with a default Heroku configuration. This enables users to spin up a fully functional Webshot instance using Heroku in just a few minutes, starting from scratch. Install the node package manager, create your heroku instance and push the configuration and you are all set!
When calling screenshots that have been generated by Webshot, the URLs reference the source website of the screenshot and allow for resizing of the image. Here are some examples from the Webshot documentation:
http://localhost:5000/api/generate?url=google.com&width=500
http://localhost:5000/api/generate?url=google.com&height=300
http://localhost:5000/api/generate?url=google.com&width=200&height=400
Check out Webshot - and don’t forget to contribute to the project on Github!
New tasks need your help within the Core Datasets Issue Registry
Open Knowledge’s Core Datasets are a selection of commonly-used datasets on a variety of topics that can be put to use for a variety of different research topics. All of the tools are free and available on Github - being able to find so many diverse, reliable and useful datasets in one place can save those of us who rely on open data a lot of time and hassle. Because so many people rely on these tools, submitting code to these tools allows your submissions to make a real and significant difference to projects all over the world. Here are some examples of the types of packages that are included:
- geoip2, a free IP geolocation database based on data from the Geolite2 MaxMind databases
- imf-weo, a copy of the International Monetary Fund World Economic Outlook database
- clinical-trials-us, javascript-based tool listing official US clinical trial outcomes from the FDA, relies on data from clinicaltrials.gov
- crime-uk, UK-specific crime data from multiple sources, including http://police.uk/data
- browser-stats, a Python based tool that collects browser usage statistics trends, primarily gathered from W3Schools log files
- and much more …
Thanks in large part to @pdehaye, the new Core Datasets Managing Curator, there has been a flurry of new activity and project additions on the Core Datasets Issue Registry. Take a look at the Issue Registry for issues that you think you could help to resolve and start to tackle it! For example, a thread has been created for the Big Mac Index Dataset. Don’t know what a Big Mac Index is? Not a problem! You don’t need to be an economist to write a script that will poll the correct datasets(note: XLS file). If you want to help out, but aren’t sure how to start or you’re having trouble, browse the easier issues and leave a comment on the relevant thread! Also, be sure to let us know in a thread that you are working on a specific project to avoid duplicating effort. Now that you know all this, go get coding!
Labs establishes organizational structure, open positions still available
Labs continues to expand and attract interest from talented developers and all manner of smarty-pantses. With more people and more projects there is more responsibility and more to get done. To that end, Labs has begun to develop an organizational structure so that all of our team members can focus on what we are best at, to prevent duplication of efforts and to make communication easier and more effective. So far, the assigned positions are:
-
@danfowler
- Team Lead
-
@loleg
- Team Lead
-
@mattfullerton
- Team Lead
-
@pdehaye
- Core Datasets Managing Curator
-
@davbre
- Advisory Group Member
-
@davidmiller
- Advisory Group Member
-
@jgkim
- Advisory Group Member
-
@jwieder
- Advisory Group Member
For more detailed information about each position, be sure to check out this thread. There are still positions available and a significant need for assistance from those with all sorts of different skills - leave a comment on the thread to let us know that you want to help step up to keep Labs growing!
It’s time to get involved
The New Year is a time for reflection of the year gone by and an opportunity to resolve to engage in good deeds for the year ahead. This year, OFKN Labs urges you to forget about silly New Years resolutions like more exercise or less carbs. Do something important with 2016 and write more code! The first thing to do is to make sure that you are a part of the Labs team by signing up. Once you have joined the Labs community, check out our Ideas page or our current Projects and find something that you would be interested in collaborating on. Do you have a plan for something we haven’t though of yet? Tell us about it on Twitter or better yet jump on the mailing list.
For all of you already contributing to Labs: keep up the great work! Open Data is important, and your efforts continue to provide transparency for critical information. With your help, Labs will continue its success into 2016. See you then!
 We make tools, apps and insights using
open stuff
We make tools, apps and insights using
open stuff


Comments