
Working with Data Package Creator
The Data Package Creator, create.frictionlessdata.io, is a revamp of the Data Packagist app that lets you create and edit and validate your data packages with ease. Read on and find out how.
Frictionless Data aims to make it effortless to transport high quality data among different tools and platforms for further analysis. At the heart of this work is the Data Package, a simple format that makes it possible to package a collection of data and attach contextual information to it before sharing it. Where tabular data is involved, the ensuing Tabular Data Package contains the dataset, its schema and descriptive metadata associated with the dataset collated in a JSON file.
The basic building block of a Data Package is its datapackage.json file. The Frictionless Data team and community have developed libraries and continue to actively support users who wish to create and work with Data Packages in Javascript, Python, Ruby, R, PHP, Java, Go, Clojure and Julia. Up until now, the Data Packagist app, which was developed as an Open Knowledge Labs initiative, has also been a helpful resource to help people create Data Packages quickly and with relative ease.
At Open Knowledge International and as part of the Frictionless Data project, we are constantly thinking about streamlining processes and making it easier for users to adopt the software we develop for use in their data work. New improvements to the Data Package specification as part of the September 2017 update have also led our team to carry out subsequent iterations on the original Data Packagist app. The outcome of this work is the Data Package Creator, which boasts a revamped user interface and additional functionality to streamline the data package creation process.
Data Package Creator is an online service that lets users generate tabular data packages from their datasets (more on the Tabular Data Package specification). Let’s see how it works.
As mentioned earlier, a data package contains a collection of data. Each unique data file is referred to as a data resource.
You can add as many resources as your data collection contains either by linking to them, uploading them from your local machine or creating them from scratch and specifying their fields. You can also edit each resource (rename, add and remove fields, et al) within the Data Package Creator.
For our example, I am looking to package data resources that contain information on three cities I am interested in: Paris, Rome and London.
- The first resource is
location.csvwhich contains city names and their coordinates. I will load this file from my local machine. Here’s what the data in thelocation.csvfile looks like.
city,location
london,"51.50,-0.11"
paris,"48.85,2.30"
rome,N/A
- The second resource is
data.csvwhich contains population information on the three cities and I will load this tabular data resource from a Github repository.
city,population
london,8787892
paris,2244000
rome,2877215
- The third resource is one that doesn’t exist yet and which I will create and add fields to in the Data Package Creator. I’ll call it
rome.csv. Once I download the data package, I will add this resource to the data package before sharing it elsewhere.
city,location
rome,"41.89,12.51"
The datapackage.json file is updated every time a resource is added, edited or removed. This JSON file can be viewed on the right hand side of the Data Package Creator by clicking on the {···} symbol to expand the section.
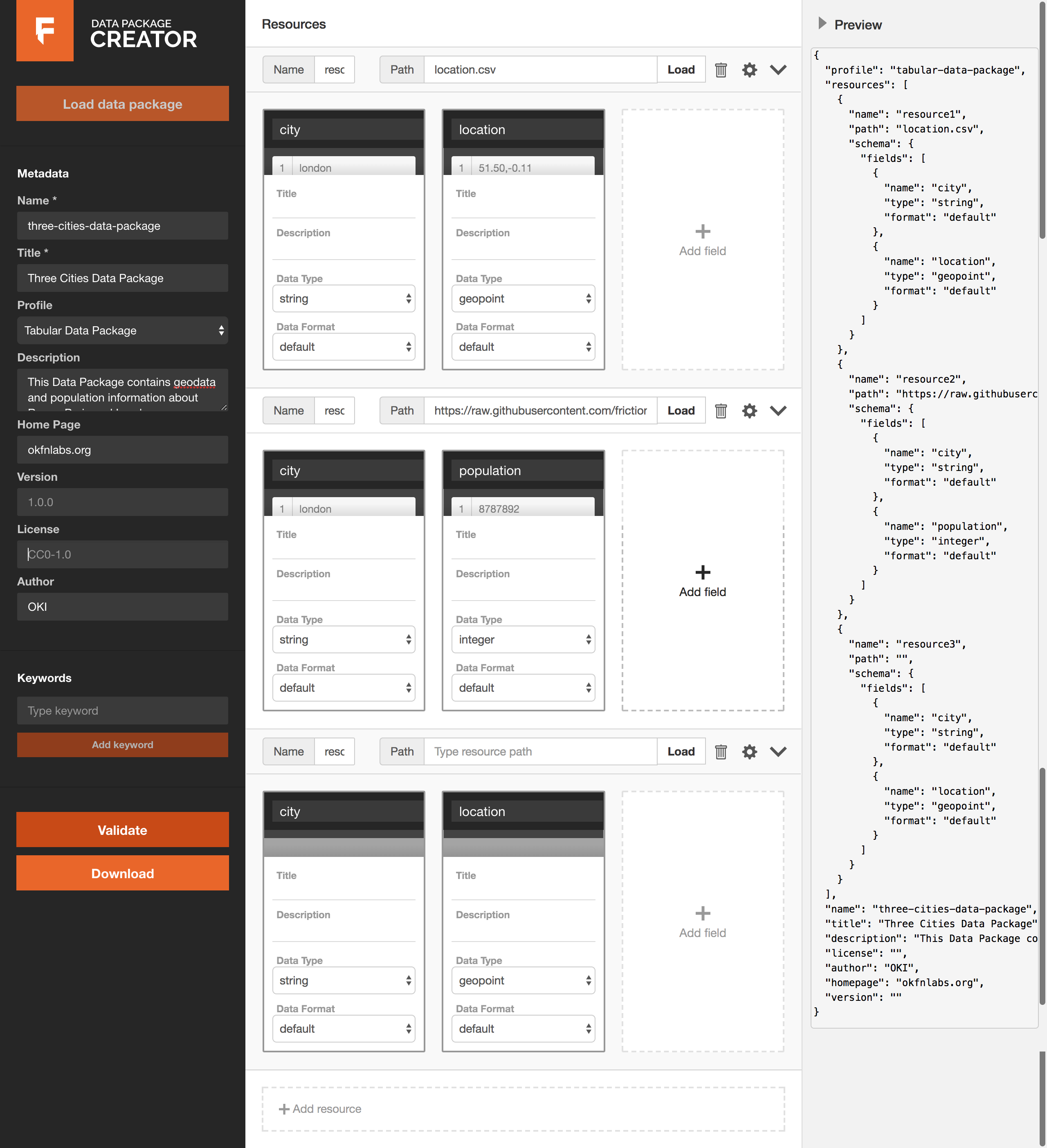 screen grab of the new Data Package Creator
screen grab of the new Data Package Creator
Metadata attached to any Data Package is also stored in the datapackage.json file. However, editing JSON files directly can be a laborious and error-prone task. The MetaData section on the left side makes it easy to write and edit descriptive metadata that will be included in your Data Package alongside your data.
The Profile Section allows you to specify what kind of Data Package you are going for. There are 3 options:
- Data Package: This can contain a collection of any type of data resource and a JSON file.
- Tabular Data Package: This collection must contain tabular data. It is possible to load data in any machine readable format - csv, tsv, xls, etc and a JSON file
- [Fiscal Data Package][fdp]: This is a subset of the tabular data package, specifically designed for use with budget and fiscal data.
The keyword section also allows you to add up to 3 tags to your Data Package, so they are more discoverable.
Before downloading your data package, click on the Validate button at the bottom of the side navigation to check whether the generated schema is valid. The Validate button prompts Data Package creator to check whether the selected profile is befitting for the resources that constitute your data package. Should you see a warning, such as the one below, it is likely that the wrong Profile is specified in the MetaData section.
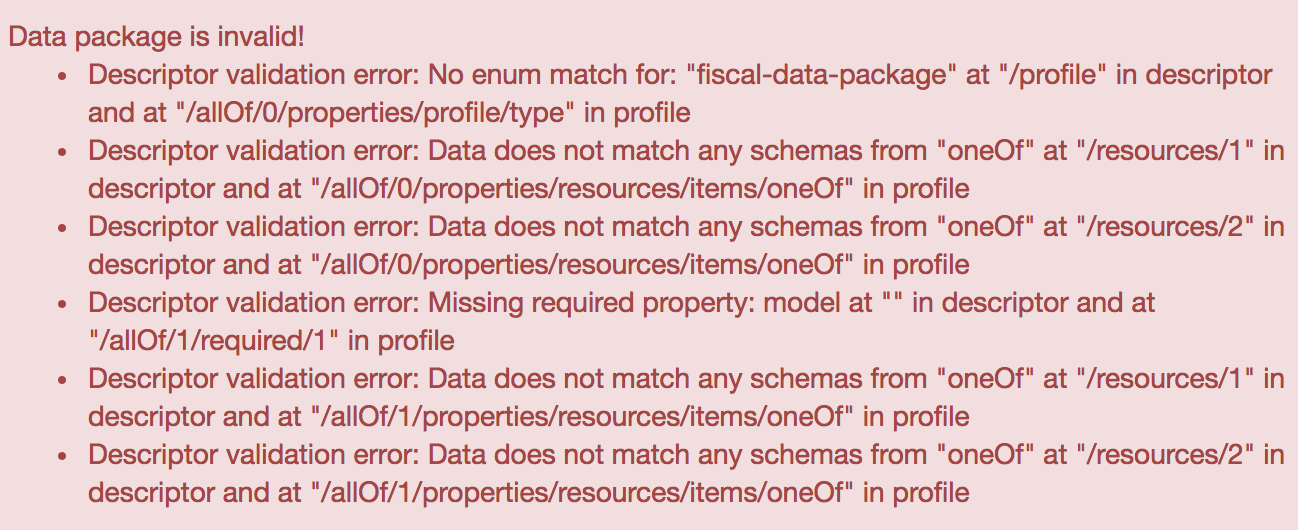 Error message that ensues on choosing the wrong data package profile. My data package is comprised of tabular data resources and the Fiscal Data Package profile is ill-suited for it. Tabular Data Package profile is most ideal.
Error message that ensues on choosing the wrong data package profile. My data package is comprised of tabular data resources and the Fiscal Data Package profile is ill-suited for it. Tabular Data Package profile is most ideal.
Aim for the eureka message below, and in case you feel stuck, reach out and we’ll work with you to resolve the issue.

Finally, click on the download button which gives you a local copy of the generated datapackage.json file, complete with your data schema and metadata attached to it. Score 1 for data provenance!
Finally, create a folder and place your downloaded datapackage.json file in it. Create a new folder within it, call it data and add all the data resources in your data package to it. You are now ready to share your data package.
Here’s what my final data package folder looks like:
Three-Cities-Data-Package
|-- datapackage.json
|-- data
|-- population.csv
|-- rome.csv
Please note, there are cases where all you would need to share is the datapackage.json file i.e. if all your resources are online and publicly accessible. For this reason, as the population data resource is publicly available and already linked in the resulting JSON file, I need not include the csv file in my final data package.
This is the code repository for Data Package Creator. We welcome your feedback and questions via our Frictionless Data Gitter chat or via Github issues.
Happy days!
 We make tools, apps and insights using
open stuff
We make tools, apps and insights using
open stuff


Comments